
Action Recognition
Andrew Gilbert, Olusegun Oshin, Richard Bowden.Overview
Recognising the actions performed by people in visual data is an important computer vision task, with applications to assisted living, surveillance and video indexing/retrieval. It has been studied for many years, and during that time certain types of algorithm have proven particularly successful. However, the performance of the state-of-the-art systems still falls far short of human performance, so there is much work still to be done.
Why is it so difficult?
Action recognition is an incredibly challenging task due to variations in the style of the action, the viewpoint of the camera, lighting etc. which change the appearance significantly without changing the action. As part of the project, novel approaches were proposed both to describe the video content, and to train the computer to recognise the type of action being performed.
Method
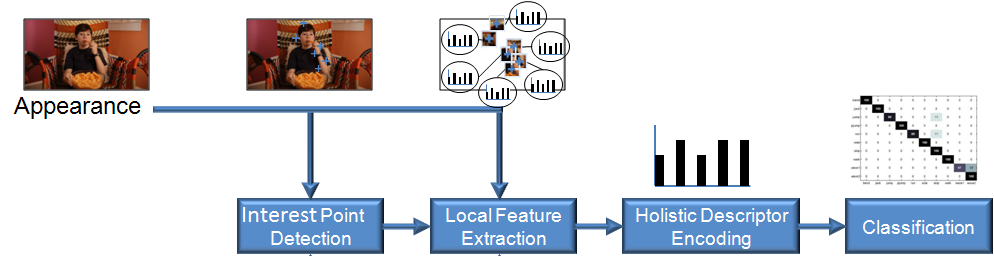
In this work, the most common action recognition pipeline was used, as shown below.
- First salient parts of the image are identified.
- Next, the information from a small region around these "interest points" is encoded into a feature representation.
- These local features are accumulated spatially and temporally across the video, providing invariance to actions occuring at different different space-time locations in the video.
- Finally, these holistic descriptors are fed into a machine learning system to recognise which type of action is occuring
In this project, advances were proposed in the second and fourth stages of this pipeline.
Local features
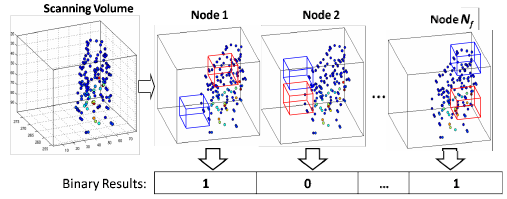
The first stage of the action recognition pipeline is generally finding the most salient regions of the image. As mentioned above, it is then common to extract local descriptions of the image in these locations. However, it is interesting to note that humans are capable of recognising actions purely from the behaviours of a small number of salient points as shown below.
Inspired by this, a descriptor was developed based on the distributions and behavious of the previously detected salient regions, throughout the video sequence. This descriptor compares the density of saliency between different regions, to produce binary vectors which are accumulated over the sequence.
Classification
A common problem in action recognition is that the number of local descriptors calculated for different image patches is immense, especially given the moves in the field towards denser interest point detection. This can make computation very expensive, and can even hurt performance as descriptions of the most important parts of the image are often lost amidst a plethora of irrelevant regions.
To solve this issue, techniques were adapted from the field of data-mining, which are extremely robust to distracting features. This allows the small number of video locations which are relevant to the action, to be automatically be recognised and extracted.
Further, we tried to simplify the problem of recognising actions by automatically finding smaller subsets of each action category. For example, the action "Get Out Car" was automatically, without human input, separated into the 2 distinct subcategories shown below (among others).
 Getting out of car (Internal shot mode)
Getting out of car (Internal shot mode)
 Getting out of car (External shot mode)
Getting out of car (External shot mode)
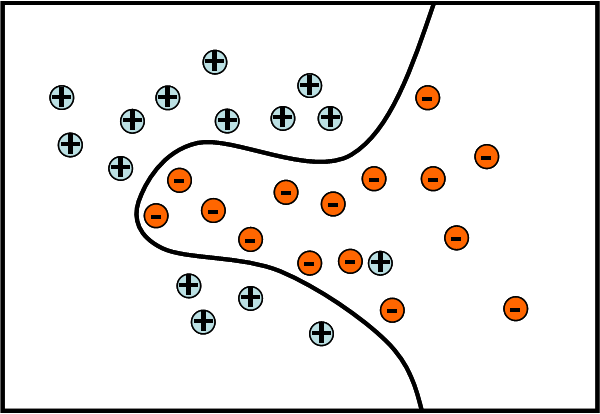
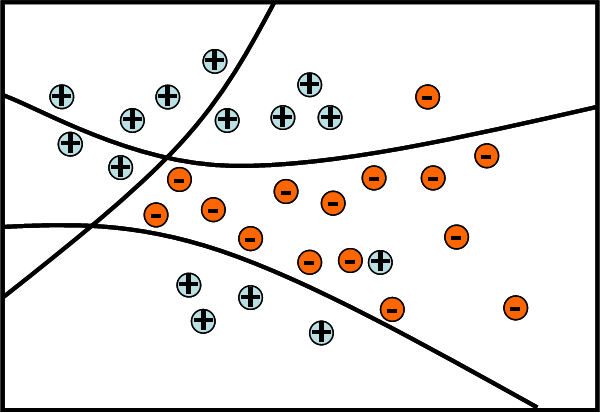
This subcategory division or "mode finding" helps to make it much easier for the algorithm to learn separations between classes. This is illustrated in the below example, where 2 types of actions (+ and -) need to be separated. If the "+" class is split into 3 different subgroups, a much simpler boundary is able to separate them.
Results
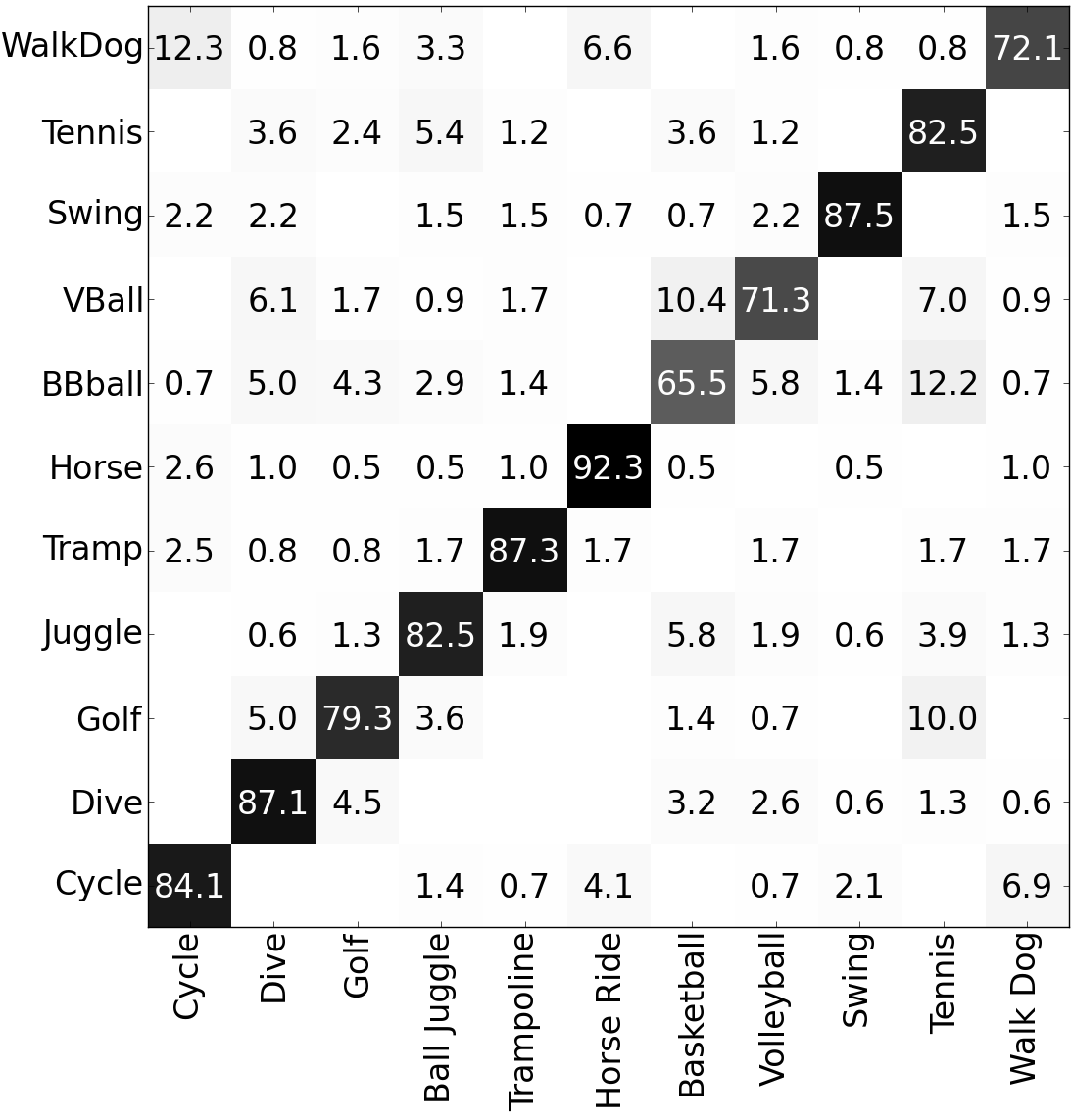
Below is an example confusion matrix for recognising different actions using the RMD features and automatic subcategory discovery.
Better performance means a darker diagonal.
Below (right) you can see an example of the features which data mining automatically learned to be relevant for an example of the "Stand Up" action. Note that despite the scene being very complex with lots of confusing motions, almost all of the extracted features lie on the salient parts of the actor who is performing the action. This is in sharp contrast to the input interest points (left), which are extracted across the entire video including irrelevant positions and frames. This smaller number of more useful feature inputs makes the recognition task significantly easier.
Publications
Capturing relative motion and finding modes for action recognition in the wild (Olusegun Oshin, Andrew Gilbert, Richard Bowden), Computer Vision and Image Understanding, 2014.
Data mining for Action Recognition (Andrew Gilbert, Richard Bowden), In Proc Asian Conference on Computer Vision (ACCV) 2014. [Poster]
Earlier related works
Action Recognition using Mined Hierarchical Compound Features (Andrew Gilbert, John Illingworth, Richard Bowden), IEEE Transactions on Pattern Analysis and Machine Intelligence, pp. 883-897, May, 2011.
There is more than one way to get out of a car: Automatic Mode Finding for Action Recognition in the Wild (Olusegun Oshin, Andrew Gilbert, Richard Bowden), In Pattern Recognition and Image Analysis. 5th Iberian Conference, (IbPRIA) 2011. Best paper Award
Capturing the Relative Distribution of Features for Action Recognition (Olusegun Oshin, Andrew Gilbert, Richard Bowden), In Face and Gesture, 2011.
Acknowledgements
This work was part of the EPSRC project “Learning to Recognise Dynamic Visual Content from Broadcast Footage“ grant EP/I011811/1.