
Learning From Broadcast Video
Matt Marter, Simon Hadfield, Richard BowdenOverview
There now exists a very large quantity of broadcast video containing a huge variety of content. We want to be able to train a computer to be able to recognise people, locations and objects so that new content can be automatically described. To be able to exploit this content for machine learning we want to use the linguistic annotation provided in scripts. This annotation is weak and unreliable and it is difficult for computers to process language as humans do. This means that different learning approaches are required.
Motivation
The ability to automatically generate descriptions for video could be useful in a variety of areas. Partially sighted people could benefit from having audio descriptions generated for content where human written descriptions do not exist. It could also allow for more powerful searching of video content without requiring detailed manual annotation.
Method
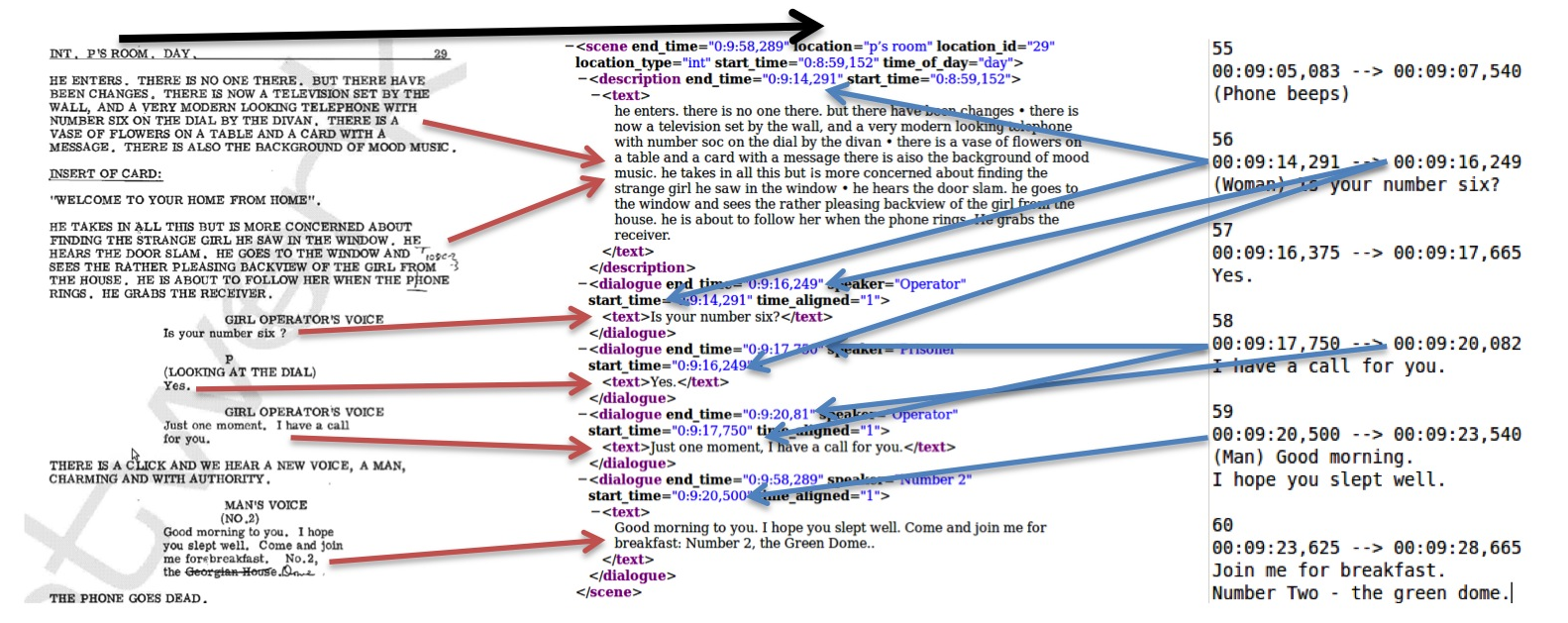
Scripts provide details of the scene location, the scene description and what the characters do and say. As an initial step for learning from broadcast video and scripts, we need to get a time alignment between them. Scripts themselves do not contain any timing information but subtitles contain timing for the dialogue. The dialogue in the subtitles can be matched to the script to provide timings for elements in the script.
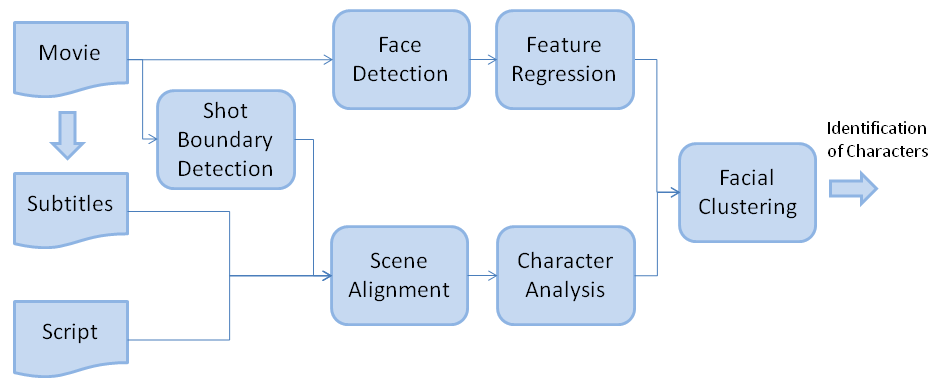
For the learning of character identities, we can use the dialogue to find which characters are present within a particular scene. We then need to use a face detector to locate the faces in the video. The detected faces are then extracted and facial landmarks are automatically located. Descriptors are extracted from the facial landmarks to describe the faces.

With all the face descriptors extracted, various techniques can be used to associate them with the names from the script and learn their appearance. One technique is to use clustering to group faces of similar appearance. These clusters can then be assigned identities from the script by looking at their size and how often the character appears in the script. Another technique involves creating models of the distribution of groups of characters and then subtracting these groups to find the space where individual characters appear. External data from the web can also be used to train machine learning models on the appearance of the actors and then applied to the characters.
Results
The video here shows an example of a segment of video from Friends where the faces have been automatically detected and labeled with the character names.
Publications
Friendly Faces: Weakly supervised character identification (Matt
Marter, Simon Hadfield, Richard Bowden), In Face and Facial
Expression Recognition from Real World Videos workshop at ICPR,
2014.
PDF
bibtex
Acknowledgements
This work was part of the EPSRC project “Learning to Recognise Dynamic Visual Content from Broadcast Footage“ grant EP/I011811/1.