
Making Sense of Sounds Data Challenge
Can machine systems categorise sound events like a human?
Update I: Results have been published! Follow this link!
Update II: Labels of the evaluation set are now available!
Humans (with no hearing impairment) use sound in everyday life constantly to interpret their surrounding environment, refocus their attention, detect anomalies and communicate through language and vocal emotional expressions. They are able to identify a large number of sounds, e.g., the call of a bird, the noise of an engine, the cry of a baby, the sound of a string instrument. They are also capable of generalising from past experience to new sounds, e.g. recognising a dulcimer or a kora as a musical instrument despite having never heard this instrument before in their life. The Making Sense of Sounds data challenge calls for machine systems to attempt to replicate this human ability.
Task description
The task is to classify audio data as belonging to one of five broad categories, which were derived from human classification. In a psychological experiment at the University of Salford, participants were asked to categorise 60 sound types, chosen so as to represent the most commonly used search terms on Freesound.org. Five principal categories were identified by correspondence analysis and hierarchical cluster analysis of the human data:
Nature
Human
Music
Effects
Urban
Within each class the data for the task consists of varying sound types, e.g., different animals in the ‘Nature’ category or different instruments in the ‘Music’ category such as ‘guitar’ and ‘mandolin’. Most of the sound types are represented by several instances themselves, coming from different recordings, e.g. different guitars. The machine classifier is therefore forced to reproduce a human capability to be successful: Humans are able to identify a hitherto unheard animal sound as belonging to an animal based upon previously established schemas, and a hitherto unheard musical instrument as a musical instrument, etc.
The data set was randomly split per category in a development set, for which the class labels are provided and a held-out evaluation set, for which the audio data will published later and the labels only after the challenge is completed. Since the allocation of specific sound types to the development and evaluation sets was (pseudo-) random, the resulting sets are (intentionally) not balanced in this respect, e.g., it is not guaranteed that the number of samples for each sound type is proportionally equal in the development set and the evaluation set or even that the sound type is represented at all in both data sets.
We recommend, of course, cross-validation on the development set, but do not suggest a split of the data set into folds. Given the nature of the data, this might be a task not to be underestimated on its own. The use of external data and data augmentation is permitted (see Rules section below).
The challenge results will be announced at the 2018 DCASE (Detection and Classification of Acoustic Scenes and Events) workshop.
Important dates:
Challenge announcement and development data set release: 8. Aug. 2018
Evaluation data set release: 1. Oct. 2018
Submission open: 1. Oct. 2018
Submission closing: 30. Oct. 2018 5. Nov. 2018 (anywhere on earth)
Challenge results announcement: 19/20. Nov. 2018
Dataset
Audio data
The audio files were taken from Freesound data base, the ESC-50 dataset and the Cambridge-MT Multitrack Download Library.
The development dataset consists of 1500 audio files divided into the five categories, each containing 300 files. The number of different sound types within each category is not balanced. The evaluation dataset consists of 500 audio files, 100 files per category. All files have an identical format: single-channel 44.1 kHz, 16-bit .wav files. All files are exactly 5 seconds long, but may feature periods of silence, i.e. a given extract may feature a sound that is shorter than the duration of the audio file.
It should be assumed that all files in this challenge are provided under the licence
CC-BY-NC 4.0 (Creative Commons, Attribution Noncommercial). This is the most restrictive licence of any file in the dataset, though some were also provided under CC0 and CC-BY. A complete listing of the exact licences and author attributions will be released at the close of the challenge. Attribution information is being withheld until then to prevent the gathering of any classification data based on the original file names.
Labels
The class labels are provided with the Logsheet_Development.csv text file. Each entry contains the broad class, the sound type and the file name separated by commas e.g., a line might read like this:
Effects,Beep,TN7.wav
Download
8/8/2018: Development data set released.
1/10/2018: Evaluation data set released.
27/11/2018: Copyright attribution for all files released.
29/11/2018: Evaluation data labels released.
Development & Evaluation data sets: Here on figshare.
Submission (closed)
The system output file to be submitted should be a CSV text file. For every file in the evaluation set, there should be an entry (line) consisting of the file name and the estimated class label separated by a comma. The output file should not contain any sound type labels. A line might read like this:
94Q.wav,Human
Submission will be via email. The address and other details will be announced with the opening of the submission system on 1. Oct. 2018. An extended abstract of up to two pages will be required with a short description of the submitted system(s). There will be no formatting requirements.
Up to four systems can be submitted per team.
There will be a ranking according to the error metric described below. It will be made public in a talk or poster at the DCASE 2018 workshop and published together with the extended abstracts here on the Making Sense of Sounds website.
Submission system (closed)
Please send the output file as attachment via email to: msos.submissions2018@gmail.com
(Do no use this submission email address for questions but the general mail address displayed at the bottom of the page)
Per team up to four systems can be submitted. Please submit each system with an email on its own.
The body of the email should contain the following information:
- System id: A short sequence of letters and digits to identify your systems. This will be used in the rankings. No spaces please!
- Author names: Names of the team members.
- Authors’ affiliations: Affiliations of the team members. Use numbers in square brackets after the author names and in front of the affiliations if there are several affiliations.
Example:
System id: UUMagicRec_1
Author names: Jane Engineer [1,2], John Scientist [2]
Authors’ affiliations:
[1] University of Nonexistence, Nowhere
[2] The Unseen University, Somewhere
As a second attachment add the required extended abstract outlining your method. Please use only PDF format! If you submit several systems, a single abstract is sufficient if it covers all systems. There are no requirements concerning the form, but of course you should give your abstract a meaningful title, mention all authors and their affiliations and provide at least one contact email address.
The reception of the submission will be acknowledged via automated return mail. If we encounter problems with your submitted file, we will contact you at the address from which the submission was sent.
Evaluation
The challenge will use average accuracy as its performance measure, that is, the number of correctly classified items (files) per class divided by the total number of items (files) per class and then averaged over all classes to arrive at a single number.
Baseline
08/10/2018: We added a strong state-of-the-art deep learning baseline for comparison. The scores on the evaluation set are:
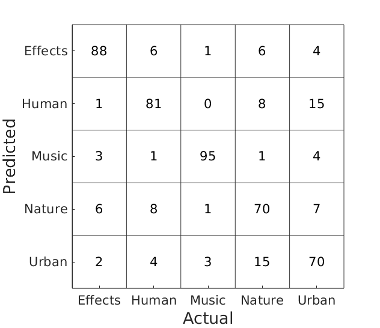
- Effects: 0.88
- Human: 0.81
- Music: 0.95
- Nature: 0.70
- Urban: 0.70
Average: 0.81
The baseline system is based on a VGG model with 8 convolutional layers, the filter size of each convolutional layer is 3x3. Batch normalisation is applied after each convolutional layer followed by a rectifier. Then a global max pooling operation on the feature maps of the last convolutional layer is utilised to summarise the feature maps to a vector. Finally, a fully connected layer is followed by a sigmoid or softmax nonlinearity to generate the probabilities of the audio classes.
Details will be published in an upcoming paper submitted to ICASSP 2019.
Rules
Development Data Set:
The Development Data Set can be manipulated, augmented or split at will.
The additional sound type labels provided in the development data set can be used. Sound type is not an evaluation criterion.
External Data:
- The use of external data is permitted. Any such external data sets must be publicly available free of charge, and must be referenced in the submission.
Pre-trained Networks/Classifiers:
- The use of pre-trained networks or other pre-trained classifier is permitted. The source of any such pre-trained network/classifier must be publicly available and referenced if it is not the author’s own. If the pre-trained network/classifier has been built by the author, the data used to train the network/classifier must comply with the “use of external data” rule above.
Evaluation Data:
The audio files in the evaluation set are to be used “blind”, for submitting evaluation results only. In particular, researchers must not listen to or display any audio, waveforms, spectrograms or other features derived from files in the evaluation set.
The evaluation data cannot be used in any way to train the submitted system. For example, the evaluation data cannot be used as part of a semi-supervised or unsupervised learning system. The use of summary statistics derived from the evaluation set are also not permitted.
To re-emphasize the “blind” rule above: The use of subjective judgements on the evaluation set are not permitted. No other way of assisting, modifying or suppressing the annotation of the evaluation set is permitted, including the use of perceived performance on the evaluation set as part of the algorithm development process.
Results
21/11/2018: Twenty-three systems (including the baseline) from 12 teams were submitted, originating both from academia and industry.
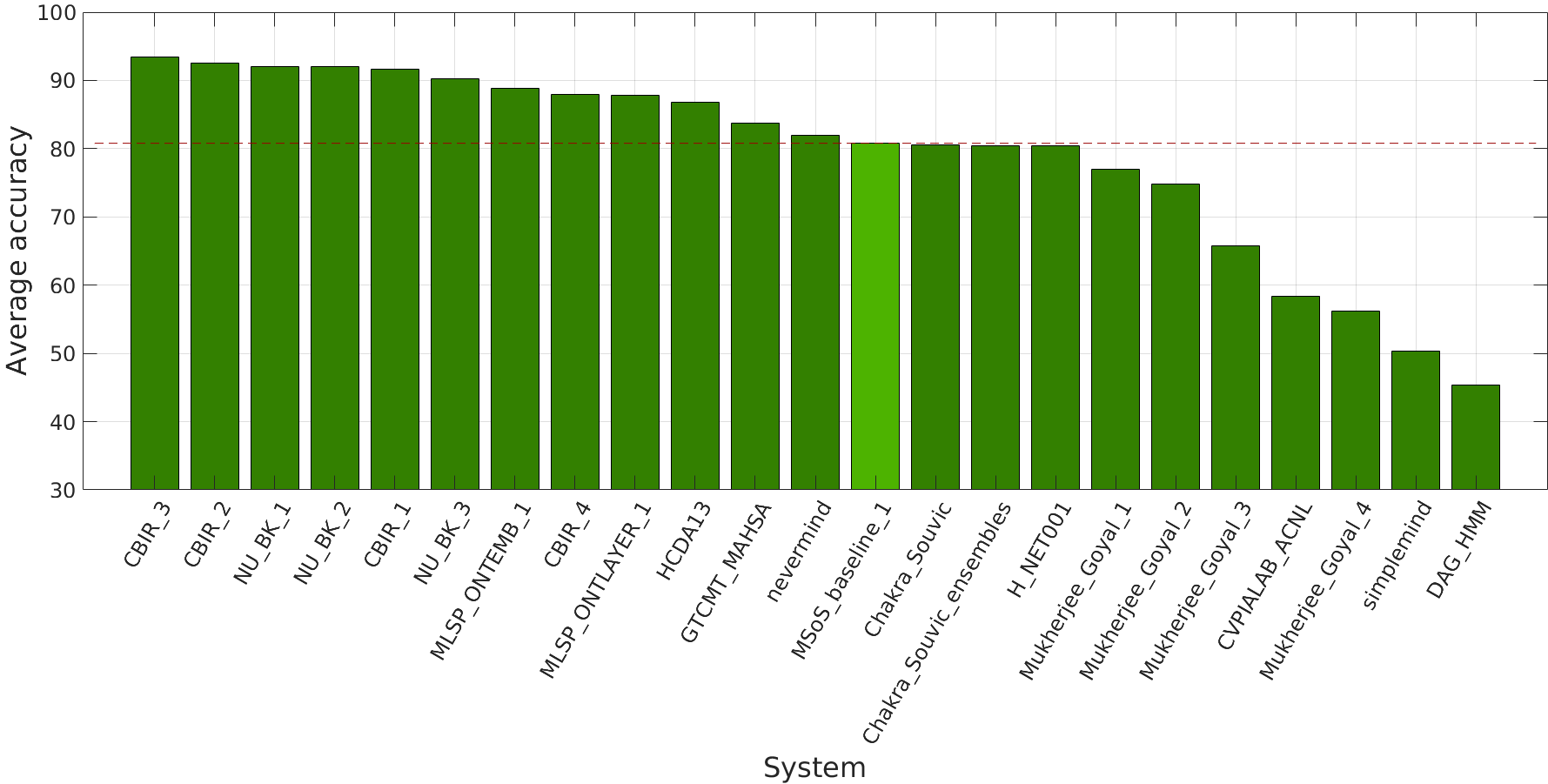
Note that in the bar graph above the results are not rounded, but for the official ranking in the table at the end of the page they are. Systems with differences in the percentage decimal place can be safely assumed as being not significantly different in their performance.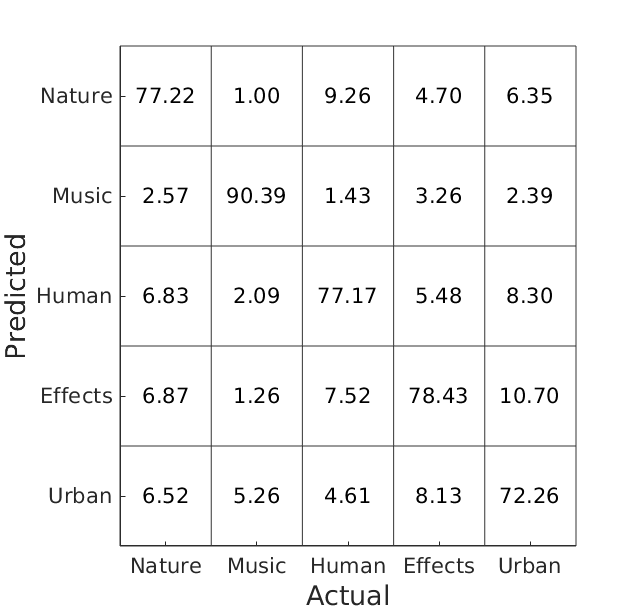
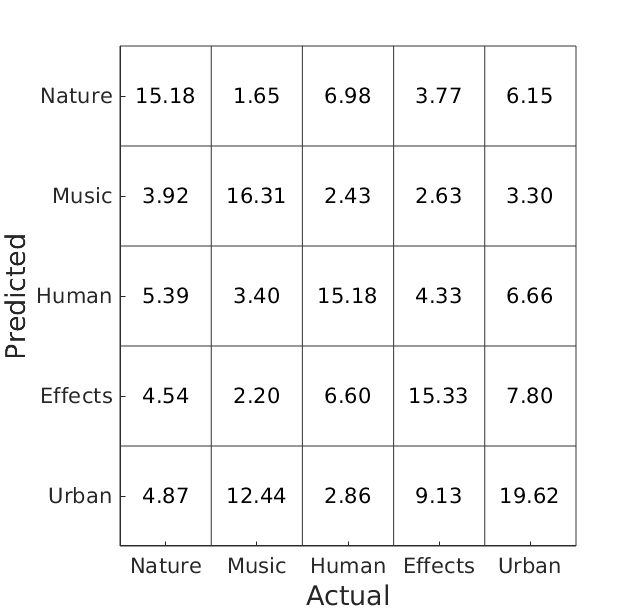
The standard deviation above is likely to be dependent on the magnitude of the mean. Accordingly the coefficient of variation (standard deviation divided by the mean) will give a more accurate picture of the variability across all systems: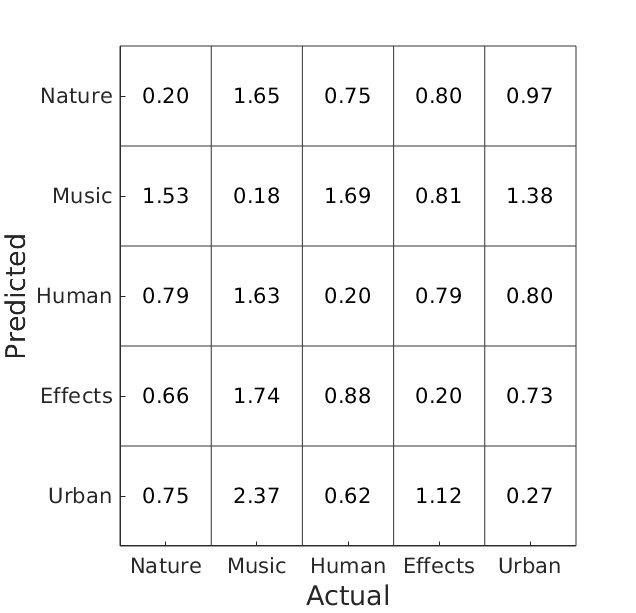
Click on the links in the system names in the table below for the confusion matrices of the individual systems and the abstracts describing the methods!
| Rank | Authors | Affiliation | System | Average | Nature | Music | Human | Effects | Urban |
|---|---|---|---|---|---|---|---|---|---|
| 1 | Tianxiang Chen, Udit Gupta | Pindrop Security Inc. | CBIR_3 | 0.93 | 0.91 | 1.00 | 0.92 | 0.95 | 0.89 |
| 1 | Tianxiang Chen, Udit Gupta | Pindrop Security Inc. | CBIR_2 | 0.93 | 0.96 | 0.97 | 0.91 | 0.90 | 0.89 |
| 3 | Bongjun Kim | Northwestern University, USA | NU_BK_1 | 0.92 | 0.89 | 1.00 | 0.92 | 0.89 | 0.90 |
| 3 | Bongjun Kim | Northwestern University, USA | NU_BK_2 | 0.92 | 0.89 | 1.00 | 0.90 | 0.91 | 0.90 |
| 5 | Tianxiang Chen, Udit Gupta | Pindrop Security Inc. | CBIR_1 | 0.91 | 0.92 | 0.97 | 0.92 | 0.87 | 0.90 |
| 6 | Bongjun Kim | Northwestern University, USA | NU_BK_3 | 0.90 | 0.88 | 0.99 | 0.89 | 0.85 | 0.90 |
| 7 | Benjamin Elizalde, Abelino Jimenez, Bhiksha Raj | Carnegie Mellon University, USA | MLSP_ONTEMB_1 | 0.89 | 0.86 | 0.99 | 0.86 | 0.89 | 0.84 |
| 8 | Tianxiang Chen, Udit Gupta | Pindrop Security Inc. | CBIR_4 | 0.88 | 0.85 | 1.00 | 0.89 | 0.81 | 0.85 |
| 8 | Abelino Jimenez, Benjamin Elizalde, Bhiksha Raj | Carnegie Mellon University, USA | MLSP_ONTLAYER_1 | 0.88 | 0.83 | 0.99 | 0.82 | 0.89 | 0.86 |
| 10 | Aggelina Chatziagapi [1], Theodoros Giannakopoulos [1] | Behavioral Signals Technologies, INC | HCDA13 | 0.87 | 0.85 | 0.98 | 0.92 | 0.79 | 0.80 |
| 11 | Mansoor Rahimat Khan, Alexander Lerch, Hongzhao Guwalgiya, Siddharth Kumar Gururani, Ashis Pati | Georgia Tech Center for Music Technology | GTCMT_MAHSA | 0.84 | 0.80 | 1.00 | 0.77 | 0.86 | 0.76 |
| 12 | Patrice Guyot | IRIT, Université de Toulouse, CNRS, Toulouse, France | nevermind | 0.82 | 0.75 | 0.97 | 0.76 | 0.91 | 0.71 |
| 13 | Yin Cao | CVSSP, University of Surrey, UK | MSoS_baseline_1 | 0.81 | 0.70 | 0.95 | 0.81 | 0.88 | 0.70 |
| 13 | Souvic Chakraborty | IIT Kharagpur | Chakra_Souvic | 0.81 | 0.81 | 0.99 | 0.75 | 0.77 | 0.71 |
| 15 | Souvic Chakraborty | IIT Kharagpur | Chakra_Souvic ensemble | 0.80 | 0.80 | 1.00 | 0.77 | 0.75 | 0.70 |
| 15 | Hadrien Jean | Ecole Normale Supérieure, Paris | H_NET001 | 0.80 | 0.98 | 0.72 | 0.80 | 0.58 | 0.94 |
| 17 | Rajdeep Mukherjee [1], Pradhumn Goyal [1], Dipyaman Banerjee [2], Kuntal Dey [2], Pawan Goyal [1] | [1] Indian Institute of Technology, Kharagpur, India [2] IBM Research - India, New Delhi, India | Mukherjee_Goyal_1 | 0.77 | 0.69 | 0.93 | 0.76 | 0.78 | 0.69 |
| 18 | Rajdeep Mukherjee [1], Pradhumn Goyal [1], Dipyaman Banerjee [2], Kuntal Dey [2], Pawan Goyal [1] | [1] Indian Institute of Technology, Kharagpur, India [2] IBM Research - India, New Delhi, India | Mukherjee_Goyal_2 | 0.74 | 0.66 | 0.90 | 0.77 | 0.79 | 0.62 |
| 19 | Rajdeep Mukherjee [1], Pradhumn Goyal [1], Dipyaman Banerjee [2], Kuntal Dey [2], Pawan Goyal [1] | [1] Indian Institute of Technology, Kharagpur, India [2] IBM Research - India, New Delhi, India | Mukherjee_Goyal_3 | 0.66 | 0.70 | 0.88 | 0.53 | 0.77 | 0.41 |
| 20 | Md Sultan Mahmud [1], Mohammed Yeasin [1], Faruk Ahmed [1], Rakib Al-Fahad [1], and Gavin M. Bidelman [2, 3, 4] | [1] Department of Electrical & Computer Engineering, University of Memphis, Memphis, TN, USA [2] School of Communication Sciences & Disorders, University of Memphis, Memphis, TN, USA [3] Institute for Intelligent Systems, University of Memphis, Memphis, TN, USA [4] University of Tennessee Health Sciences Center, Department of Anatomy and Neurobiology, Memphis, TN, USA | CVPIALAB_ACNL | 0.58 | 0.52 | 0.84 | 0.52 | 0.65 | 0.39 |
| 21 | Rajdeep Mukherjee [1], Pradhumn Goyal [1], Dipyaman Banerjee [2], Kuntal Dey [2], Pawan Goyal [1] | [1] Indian Institute of Technology, Kharagpur, India [2] IBM Research - India, New Delhi, India | Mukherjee_Goyal_4 | 0.56 | 0.59 | 0.64 | 0.47 | 0.67 | 0.44 |
| 22 | Patrice Guyot | IRIT, Université de Toulouse, CNRS, Toulouse, France | simplemind | 0.50 | 0.46 | 0.77 | 0.43 | 0.63 | 0.23 |
| 23 | Stavros Ntalampiras | University of Milan, Italy | DAG_HMM | 0.45 | 0.46 | 0.31 | 0.66 | 0.25 | 0.59 |
Contact
MSoS.challenge@gmail.com