Total Capture: 3D Human Pose Estimation Fusing Video and Inertial Sensors
Matthew Trumble, Andrew Gilbert, Charles Malleson, Adrian Hilton and John Collomosse, Centre for Vision, Speech & Signal Processing University of Surrey, United Kingdom appeared atBritish Machine Vision Conference, BMVC 2017 (ORAL)
Abstract
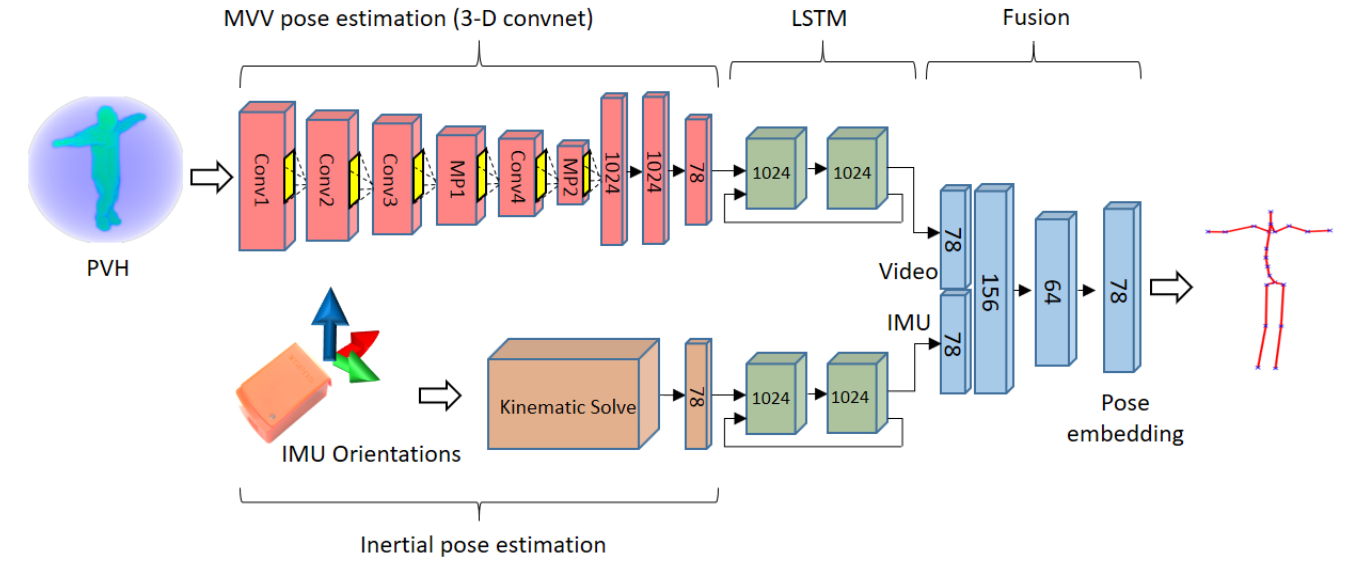
We present an algorithm for fusing multi-viewpoint video (MVV) with inertial measurement unit (IMU) sensor data to accurately estimate 3D human pose. A 3-D convolutional neural network is used to learn a pose embedding from volumetric probabilistic visual hull data (PVH) derived from the MVV frames. We incorporate this model within a dual stream network integrating pose embeddings derived from MVV and a forward kinematic solve of the IMU data. A temporal model (LSTM) is incorporated within both streams prior to their fusion. Hybrid pose inference using these two complementary data sources is shown to resolve ambiguities within each sensor modality, yielding improved accuracy over prior methods. A further contribution of this work is a new hybrid MVV dataset (TotalCapture) comprising video, IMU and a skeletal joint ground truth derived from a commercial motion capture system. The dataset is available online at http://cvssp.org/data/totalcapture/
Paper

Total Capture: 3D Human Pose Estimation Fusing Video and Inertial Sensors
Matthew Trumble, Andrew Gilbert, Charles Malleson, Adrian Hilton, and John Collomosse,
BMVC 2017
![]()
![]()
![]()
![]()
TotalCapture Dataset
As part of this work, we make public the 3D human pose dataset TotalCapture; this is the first dataset to have fully synchronised muli-view video, IMU and Vicon labelling for a large number of frames (∼1.9M), for many subjects, activities and viewpoints. The data was captured indoors in a volume measuring roughly 4x6m with 8 calibrated full HD video cameras recording at 60Hz on a gantry suspended at approximately 2.5 metres. The dataset can be downloaded from http://cvssp.org/data/totalcapture/.
Citation
@inproceedings{Trumble:BMVC:2017,
AUTHOR = "Trumble, Matt and Gilbert, Andrew and Malleson, Charles and Hilton, Adrian and Collomosse, John",
TITLE = "Total Capture: 3D Human Pose Estimation Fusing Video and Inertial Sensors",
BOOKTITLE = "2017 British Machine Vision Conference (BMVC)",
YEAR = "2017",
}