The Binaural Synthesis Toolkit¶
The binaural synthesis toolkit (VISR_BST) is an extensible set of components for realtime and offline binaural synthesis.
This section consists of two parts. First, Section Tutorial introduces the BST in a tutorial-style form. After that, Section Component reference describes all components and helper classes and functions in detail.
Tutorial¶
Note
This tutorial is based on the AES e-Brief:
Franck, A., Costantini, G., Pike, C., and Fazi, F. M., “An Open Realtime Binaural Synthesis Toolkit for Audio Research,” in Proc. Audio Eng. Soc. 144th Conv., Milano, Italy, 2018, Engineering Brief.”
Binaural synthesis has gained fundamental importance both as a practical sound reproduction method and as a tool in audio research. Binaural rendering requires significant implementation effort, especially if head movement tracking or dynamic sound scenes are required, thus impeding audio research. For this reason we propose the Binaural Synthesis Toolkit (BST), a portable, open source, and extensible software package for binaural synthesis. In this paper we present the design of the BST and the three rendering approaches currently implemented. In contrast to most other software, the BST can easily be adapted and extended by users. The Binaural Synthesis Toolkit is released as an open software package as a flexible solution for binaural reproduction and to foster reproducible research in this field.
Introduction¶
Binaural synthesis aims at recreating spatial audio by recreating binaural signals at the listener’s ears [B1], using either headphones or loudspeakers. While binaural technology is an area of active research for a long time, the shift of music consumption towards mobile listening, object-based content, as well as the increasing importance of augmented and virtual reality (AR/VR) applications emphasize the increasing significance of binaural reproduction. In addition, binaural techniques are an important tool in many areas of audio research and development, from basic perceptual experiments to auralization of acoustic environments or the evaluation of spatial sound reproduction [B2].
Regardless of the application, synthesizing binaural content invariably comprises a number of software building blocks, e.g., HRTF/BRIR selection and/or interpolation, signal filtering, modeling and applying interaural time and level differences, etc. [B3]. Dynamic binaural synthesis significantly increases the plausibility of reproduction by including dynamic cues as head movements [B4], but requires both a real-time implementation and additional DSP functionality as time-variant delays, dynamic filter updates, and filter crossfading techniques. This implies a considerable implementation effort for research based on binaural synthesis, increases the likelihood of errors due to implementation effects, and makes it difficult to reproduce or evaluate the research of others. This argument is in line with the increasing importance of software in (audio) research, e.g., [B5], and the generally growing awareness of reproducible research, e.g., [B6].
For this reason we introduce the Binaural Synthesis Toolkit (BST) as an open source, portable, and extensible software library for real-time and offline binaural synthesis. Our intention is to provide baseline implementations for main binaural rendering schemes as well as DSP building blocks that enable the modification of existing renderers as well as the implementation of new rendering approaches.
The objective of its paper is to describe the architecture of the BST to enable its use as well as its adaptation by the audio community. In essence, the BST is a set of processing components implemented within the VISR — an open software rendering framework for audio rendering [B7] — and preconfigured renderers built upon these components. At the moment, three renderers are provided, namely HRIR-based dynamic synthesis, e.g., [B4], virtual loudspeaker synthesis (also termed room scanning [B8]), and binaural rendering based on higher order Ambisonics (HOA), e.g., [B9]. BRIR/HRIR data can be provided in the AES69-2015 format (SOFA) [B10] (http://www.sofaconventions.org), allowing for arbitrary HRIR/BRIR measurement grids, and enabling the use of a wide range of impulse response datasets.
Compared to existing software projects supporting binaural synthesis, for instance Spat [B9] or the SoundScape Renderer (SSR) [B11], the BST offers several new possibilities. On the one hand, its modular structure is designed for easy adaptation and extension rather than providing a fixed functionality. To a large extent, this is achieved by the Python language interface of the underlying VISR, and the fact that most high-level BST components are implemented in Python. On the other hand, while most other software projects are mainly for real-time use, BST components can be used both in real-time and in fully parametrizable offline simulations using the same code base. This makes the BST an effective tool for algorithm development. Again, these capabilities are enabled mainly by the Python language integration of the BST and the underlying VISR.
This paper is structured as follows. The underlying VISR framework and how its features influence the design and the uses of the BST is briefly outlined in Sec. Introduction. Section Preconfigured Binaural Renderers discusses the three rendering approaches currently implemented in the BST, their use, configuration, and optional features. The main building blocks of these renderers, which can also be used to adapt the BST or to implement different synthesis methods, are outlined in section Sec. Rendering Building Blocks. Section Application Examples shows practical examples of using the BST, while Sec. Conclusion summarizes the paper.
The VISR Framework¶
The binaural synthesis toolkit is based on the VISR (Versatile Interactive Scene Renderer) framework, an open-source, portable, and extensible software for audio processing [B7]. It is being developed as part of the S3A project (http://www.s3a-spatialaudio.org) [B12]. At the moment, it is supported on Linux (Intel and Raspberry Pi), Mac OS X, and Windows. VISR is a general-purpose audio processing software with emphasis on, but not limited to, multichannel and object-based audio. This section outlines the main features of the VISR framework and the implications on design and usage of the BST.
Component-Based Design¶
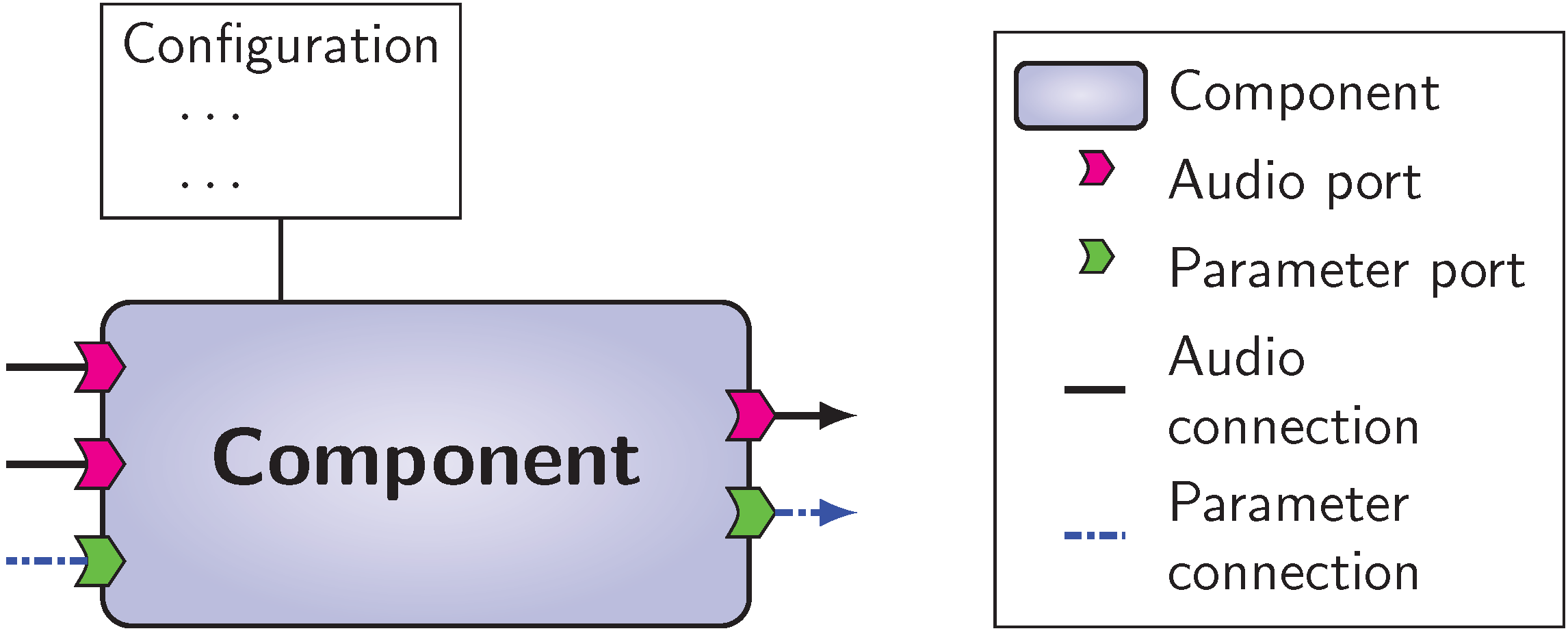
General interface of a VISR component.
VISR is a software framework, which means that it enables a systematic reuse of functionalities and is designed for extension by users. To this, all processing tasks are implemented within components, software entities that communicate with other components and the external environment through a defined, common interface. Fig. General interface of a VISR component. depicts the general structure of a component.
Ports¶
Data inputs and outputs to components are represented by ports.
They enable configurable, directional flow of information between components or with the outside environment.
There are two distinct types of ports: audio and parameter ports.
Audio ports accept or create multichannel audio signals with an arbitrary, configurable number of single/mono audio signal waveforms, which is referred as the width of the port.
Audio ports are configured with unique name, a width and a sample type such as float or int16.
Parameter ports, on the other hand, convey control and parameter information between components or from and to the external environment.
Parameter data is significantly more diverse than audio data.
For example, parameter data used in the BST includes vectors of gain or delay values, FIR or IIR filter coefficients, audio object metadata, and structures to represent the listener’s orientation.
In addition to the data type, there are also different communication semantics for parameters.
For example, data can change in each iteration of the audio processing, be updated only sporadically, or communicated through messages queues.
In VISR, these semantics are termed communication protocols and form an additional property of a parameter port.
The semantics described above are implemented by the communication protocols SharedData, DoubleBuffering, and MessageQueue, respectively.
Several parameter types feature additional configuration data, such as the dimension of a matrix parameter.
In the VISR framework, such options are passed in ParameterConfig objects.
This allows extensive type checking, for instance to ensure that only matrix parameter of matching dimensions are connected.
Combining these features, a parameter port is described by these properties: a unique name, a parameter type, a communication protocol type and an optional parameter configuration object.
Hierarchical Signal Flows¶
To create and reuse more complex functionality out of existing building blocks, VISR signal flows can be structured hierarchically. To this end, there are two different kinds of components in VISR, atomic and composite. They have the same external interface, that means that they can be used in the same way. Figures Atomic VISR component. and Composite VISR component. schematically depict these two types.
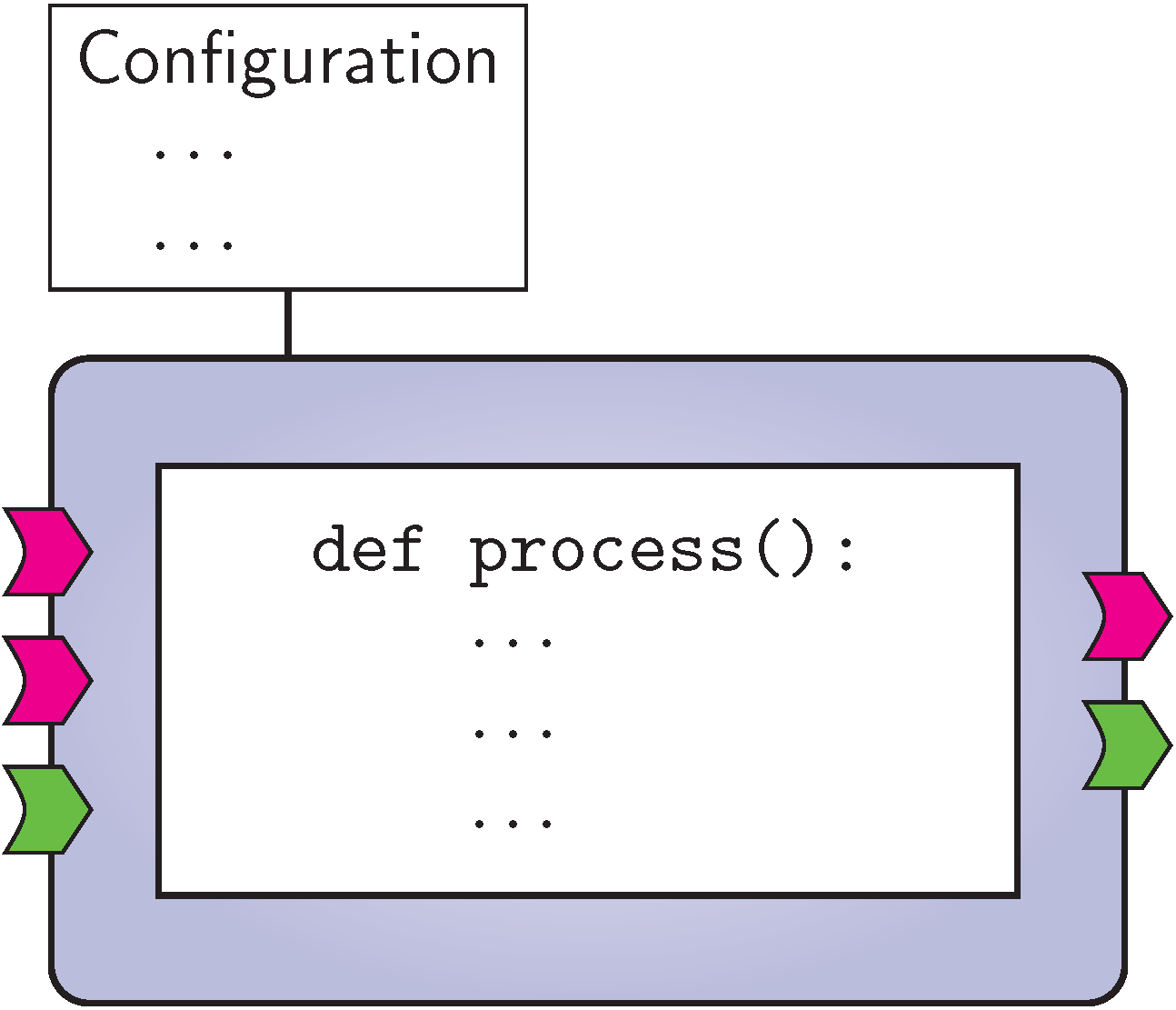
Atomic VISR component.
Atomic components implement processing task in program code, e.g., in C++ or Python.
They feature a constructor which may take a variety of configuration options to tailor the behaviour of the component and to initialize its state.
The operation of an atomic component is implemented in the process method.
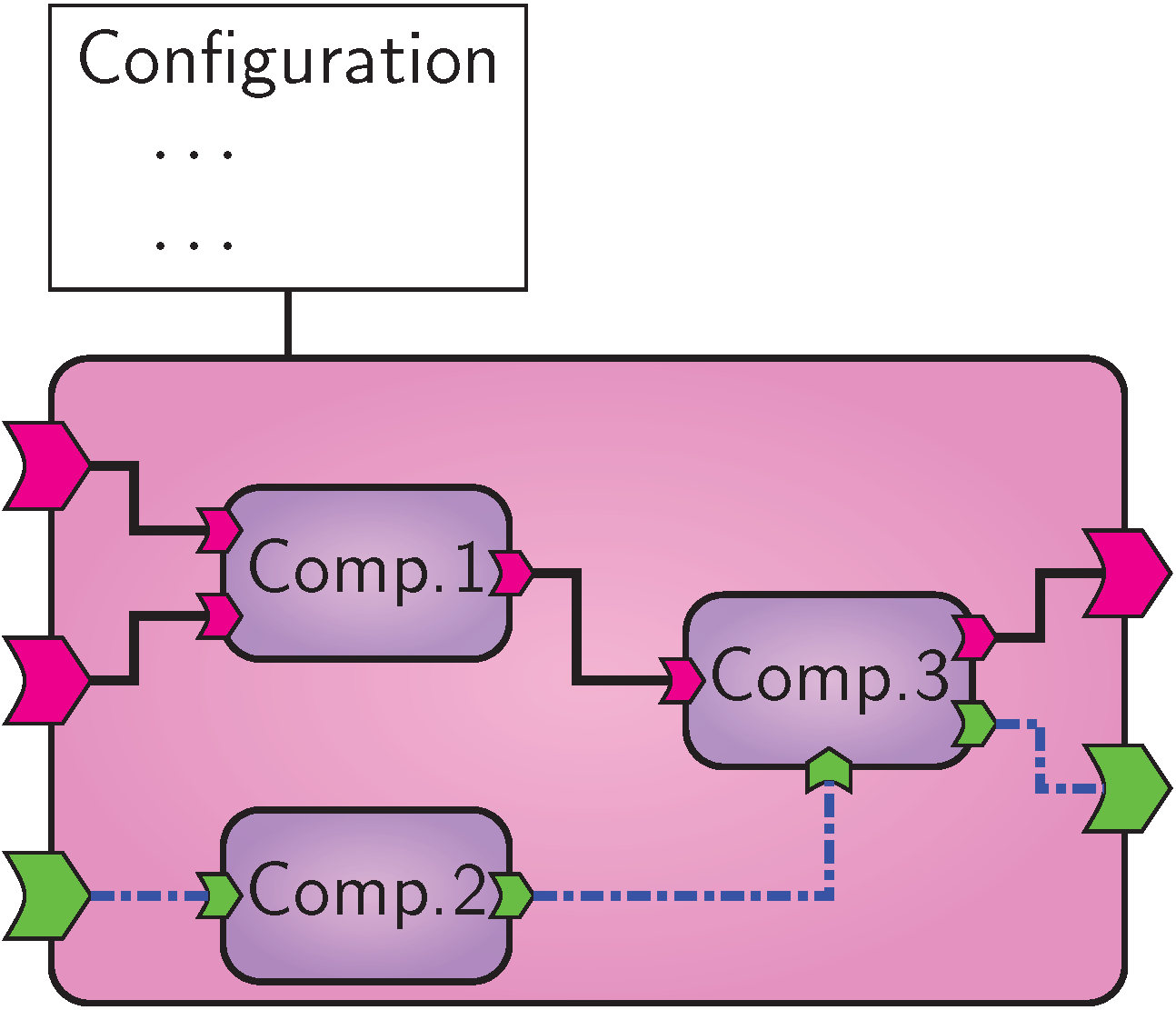
Composite VISR component.
In contrast, a composite component contains a set of interconnected components (atomic or composite) to define its behaviour. This allows the specification of more complex signal flows in terms of existing functionality, but also the reuse of such complex signal flows. As their atomic counterparts, they may take a rich set of constructor options. These can control which contained components are constructed, how they are configured, and how they are connected. It is worth noting that nested components do not impair computational efficiency because the hierarchy is flattened at initialisation time and therefore not visible to the runtime engine.
This hierarchical structure has far-reaching consequences for the design and the use of the BST. Firstly, it allows for an easy use of existing VISR components in BST components. Secondly, BST renderers can easily be augmented by additional functionality, such as receiving and decoding of object metadata or headtracking information, by wrapping it into a new composite component. Thirdly, BST functionality can be conveniently integrated into larger audio applications implemented in the VISR, for instance the transaural loudspeaker array rendering described in Sec. Transaural Loudspeaker Array.
Standard Component Library¶
The runtime component library (rcl) of the VISR framework contains a number of components for general-purpose DSP and object-based audio operations.
They are typically implemented in C++ and therefore relatively efficient.
The rcl library includes arithmetic operations on multichannel signals, gain vectors and matrices, delay lines, FIR and IIR filtering blocks, but also network senders and receivers and
components for decoding and handling of object audio metadata.
Runtime Engine¶
A key objective of the VISR framework is to enable users to focus on their processing task – performed in
a component – while automating tedious tasks, such as error checking, communication between components,
or interfacing audio hardware, as far as possible.
The rendering runtime library (rrl) serves this purpose. Starting from a top-level component,
it is only necessary to construct an object of type AudioSignalFlow for this component. All operations
from consistency checking to the initialization of memory buffers and data structures for rendering is
performed by this object. The audiointerfaces library provides abstractions for different audio interface
APIs (such as Jack, PortAudio, or ASIO). Realtime rendering is started by connecting the SignalFlow
object to an audiointerfaces object.
Python interface¶
While the core of the VISR framework is implemented in C++, it provides a full application programming interface (API) for the Python programming language. This is to enable users to adapt or extend signal flows more productively, using an interpreted language with a more accessible, readable syntax and enabling the use of rich libraries for numeric computing and DSP, such as NumPy and SciPy [B13]. The Python API can be used in three principal ways:
- Configuring and running signal flows
- Components can be created and configured from the interactive Python interpreters or script files. This makes this task fully programmable and removes the need for external scripts to configure renders. In the same way, audio interfaces can be configured, instantiated and started from within Python, enabling realtime rendering from within an interactive interpreter.
- Extending and creating signal flow
- As described above, complex signal flows are typically created as composite components.
This can be done in Python by deriving a class from the base class
visr.CompositeComponent. The behavior of the signal flow is defined in the class’ constructor by creating external ports, contained components, and their interconnections. Instances of this class can be used for realtime rendering from the Python interpreter, as described above, or from a standalone application. Most of the BST renderer signal flows are implemented in this way, ensuring readability and easy extension by users. - Adding atomic functionality
- In the same way as composites, atomic components can be implemented by deriving from
visr.AtomicComponent. This involves implementing the constructor set up the component and theprocess()method that performs the run-time processing. The resulting objects can be embedded in either Python or C++ composite components (via a helper classPythonWrapper). In the BST toolkit, the controller components that define the logic of the specific binaural rendering approaches are implemented as atomic components in Python. This language choice allows for rapid prototyping, comprehensible code, and easy adaptation.
Offline Rendering¶
By virtue of the Python integration, signal flows implemented as components are not limited to realtime rendering, but can also be executed in an offline programming environment. Because the top-level audio and parameter ports of a component can be accessed externally, dynamic rendering features such as moving objects or head movements can be simulated in a deterministic way. In the majority of uses, this is most conveniently performed in an interactive Python environment. Applications of this feature range from regression tests of atomic components or complex composite signal flows, performance simulations, to offline rendering of complete sound scenes. A full characterization of the offline rendering support is beyond the scope of this paper, interested readers are referred to [B7].
Use in multiple software environments¶
In addition to realtime rendering and offline Python scripting, VISR components can also be embedded into audio software environments such as digital audio workstations (DAWs) plugins, or Max/MSP or Pd externals. This means that parts of the BST can be used from these applications, creating new tools and integrating into the workflow of more researchers and creatives. Support libraries are provided to ease this task by reducing the amount of code required for this embedding. Again, a full discussion of this paper is beyond the scope of this paper, see [B7] for a discussion.
Preconfigured Binaural Renderers¶
The VISR Binaural Synthesis Toolkit contains prepackaged, configurable renderers (or signal flows) for three major binaural synthesis strategies. They are implemented as composite VISR components in Python. On the one hand, this means that they can be readily used either as standalone binaural renderers or as part of larger audio processing schemes. On the other hand, the use of Python allows for easy modification and extension. This section describes the general structure and the configuration options of these three renderers.
Features common to all approaches, such as an option to include headphone transfer function (HPTF) compensation filters, are not described here.
Entities such as components, ports, or configuration options are set in a monospaced font, e.g., input.
Dynamic HRIR-Based Synthesis¶
This approach renders sound objects, typically point sources or plane waves represented by position metadata and a mono signal, using spatial datasets of head-related impulse responses (HRIR) or, equivalently, head-related transfer functions (HRTFs), e.g., [B3][B4]. This approach is widely used in audio research and for practical reproduction and is well-suited for object-based audio as well as AR/VR applications. In its basic form, it synthesizes sound scenes under freefield conditions, and is therefore often augmented by a reverberation engine, e.g., [B14].
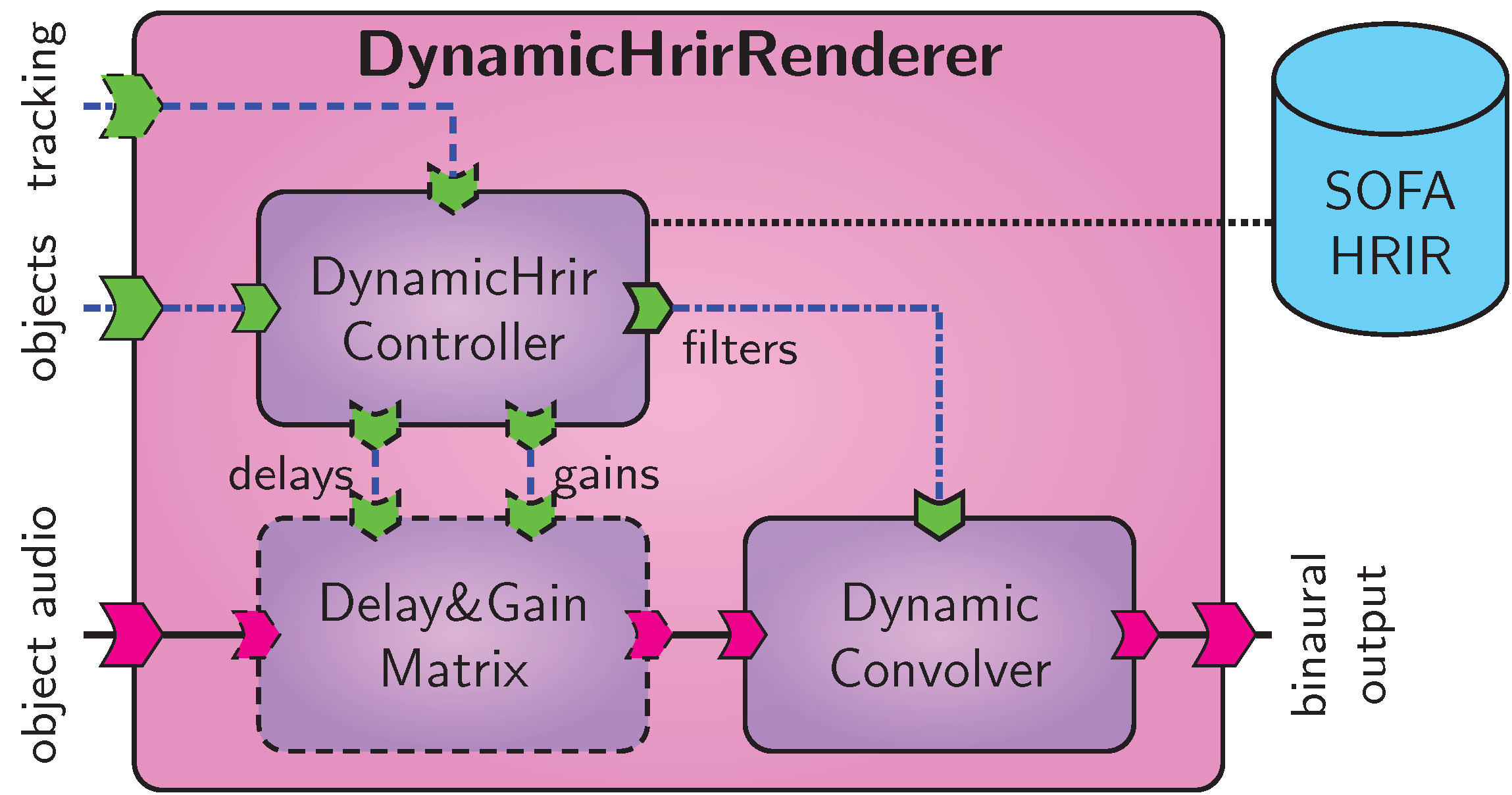
Dynamic binaural synthesis rendering component. Optional parts are dashed.
The signal flow of the BST dynamic HRIR renderer is shown in Dynamic binaural synthesis rendering component. Optional parts are dashed..
It is implemented as a composite VISR component named DynamicHrirRenderer.
The logic of the synthesis is encapsulated in the atomic component DynamicHrirController.
It receives object metadata and determines a pair of HRIR filters for each object, which are transmitted to the DSP components.
The controller is initialized with a spatial HRIR dataset and the corresponding grid locations of the IRs.
Audio object metadata, including positions and levels, are received through the parameter input port objects.
If present, the listener’s head orientation is received through the optional input tracking and incorporated in the HRIR calculation.
At the moment, two HRIR calculation methods are supported: nearest-neighbour selection and barycentric interpolation using a Delaunay triangulation, e.g., [B15].
The generated IRs, one per sound object and ear, are transmitted through the output port filters to the DynamicConvolver component, which performs time-variant MIMO (multiple-input, multiple-output) FFT-based convolution of the object audio signals and combines them into binaural output.
Depending on the configuration, the DynamicConvolver uses crossfading to reduce audible artifacts when changing filters.
The HRTF dataset, including the measurement position grid, can be provided in the AES69:2015 (SOFA) format [B10].
Optionally the rendering component accepts preprocessed datasets where the HRIRs are time-aligned and the onset delays are kept apart (e.g., in the Data.Delay field of the SOFA format).
Applying the delays separately can improve HRIR interpolation quality, reduces audible effects when updating filters, and can therefore enable the use of coarser HRIR datasets, e.g., [B3].
Because the pure delay part of the HRIRs dominates the ITD cue of the synthesized binaural signal, this also provides a means to use alternative ITD models instead of the measured IR delays, or to implement ITD individualization [B16].
In the same way, the filter gain may be calculated separately, for instance to simulate near-field source effects [B14].
In either of these cases, the dynamic delay and/or gain coefficients are calculated in the DynamicHrirController, and the optional component DelayGainMatrix is instantiated to apply these values prior to the convolution.
As described in Sec. Delay Lines: Vectors and Matrices, the delay/gain components support configurable fractional delay filtering and smooth parameter updates, thus ensuring audio quality and reducing audible artifacts in dynamic rendering scenarios.
Higher Order Ambisonics-Based Synthesis¶
A second approach, termed HOA (Higher Order Ambisonics)-based synthesis, is based on a spherical harmonics (SH) representation of a spatial sound scene, i.e., higher-order B-format. First-order B-format binaural synthesis has been proposed, e.g., in [B17][B18], and extended to higher Ambisonic orders, e.g., [B19]. This scene-based rendering approach forms, for example, the basis of the spatial audio synthesis in Facebook’s Audio360 Google’s Resonance Audio SDK https://github.com/resonance-audio/resonance-audio-web-sdk.
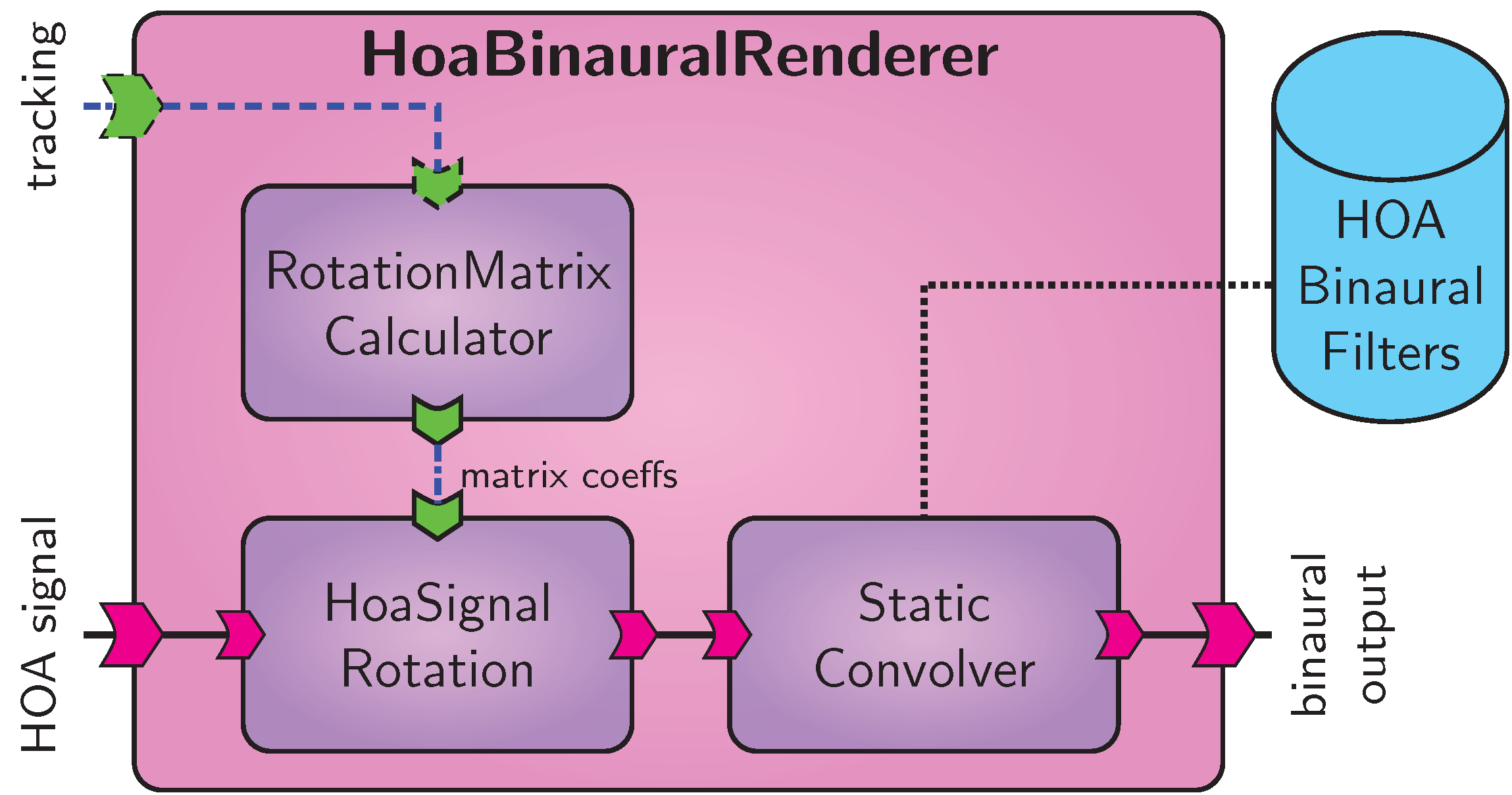
Binaural synthesis based on HOA.
The signal flow of the generic HOA synthesis renderer is depicted in Fig. Binaural synthesis based on HOA..
The component HoaBinauralRenderer accepts a HOA input signal, i.e., higher-order B-format, of a selectable order \(L\), consisting of \((L+1)^2\) channels.
If head tracking is enabled, the component RotationMatrixCalculator computes a rotation matrix for spherical harmonics using a recurrent formula [B20].
These coefficients are applied to the B-format signal in the gain matrix component HoaSignalRotation, effectively rotating the sound field to compensate for the listener’s orientation.
The component of this signal are filtered with a bank of \((L+1)^2\) static FIR filters for each ear [B19] in the StaticConvolver component, which also performs an ear-wise summation of the filtered signals to yield the binaural output signal.
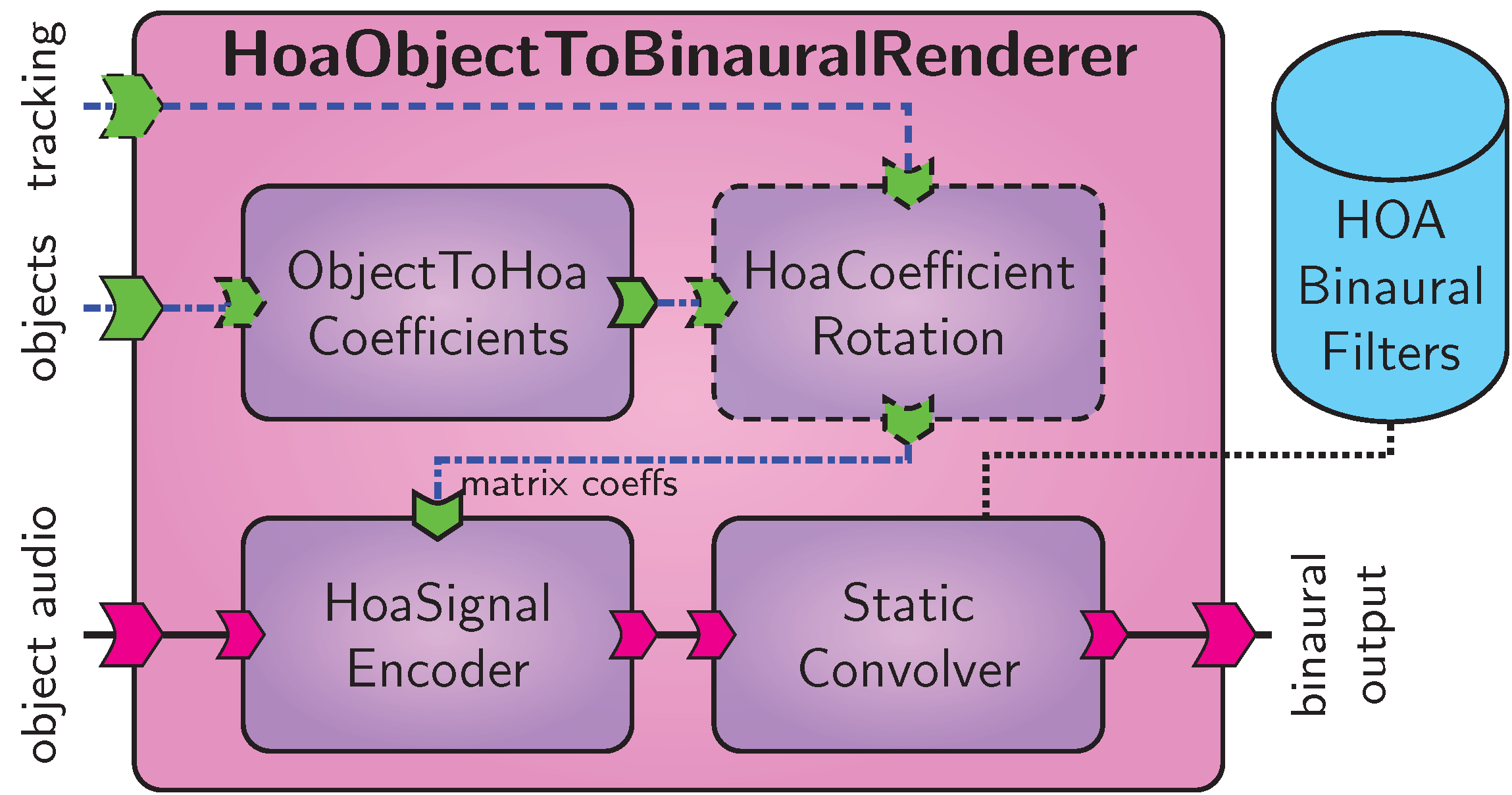
HOA binaural synthesis of object-based scenes.
Figure HOA binaural synthesis of object-based scenes. shows a variant of the HOA synthesis that operates on an object-based scene.
Component ObjectToHoaCoefficients transforms the object metadata into a set of SH coefficients for each object. If head tracking is active, the component HoaCoefficientRotation receives orientation data from the optional tracking input and applies a rotation matrix to the HOA coefficients. The HoaSignalEncoder component uses these data to encode the object signals into a B-format signal. This representation is transformed to a binaural signal in the same way as in the generic HOA binaural renderer.
The advantage of this approach is that the rotation is performed on the SH coefficients, that is a much lower rate than the audio sampling frequency, and is consequently more efficient.
Virtual Loudspeaker Rendering/ Binaural Room Scanning¶
The third principal approach implemented in the BST, denoted as virtual loudspeaker rendering, uses binaural room impulse responses of a multi-loudspeaker setup in a given acoustic environment to recreate the listening experience in that room. For this reason it is also referred to as binaural room scanning [B8][B4]. Headtracking can be used to incorporate the listener’s orientation by switching or interpolating between BRIR data provided for a grid of orientations. While the BST supports both 2D and 3D grids, exiting datasets, e.g., [B21][B22] are typically restricted to orientations in the horizontal plane because of the measurement effort and data size. In contrast to the aforementioned methods, this approach does not operate on audio objects but on loudspeaker signals. It is therefore used to reproduce channel-based content or to transform the output of loudspeaker-based rendering methods to binaural, e.g., [B23].
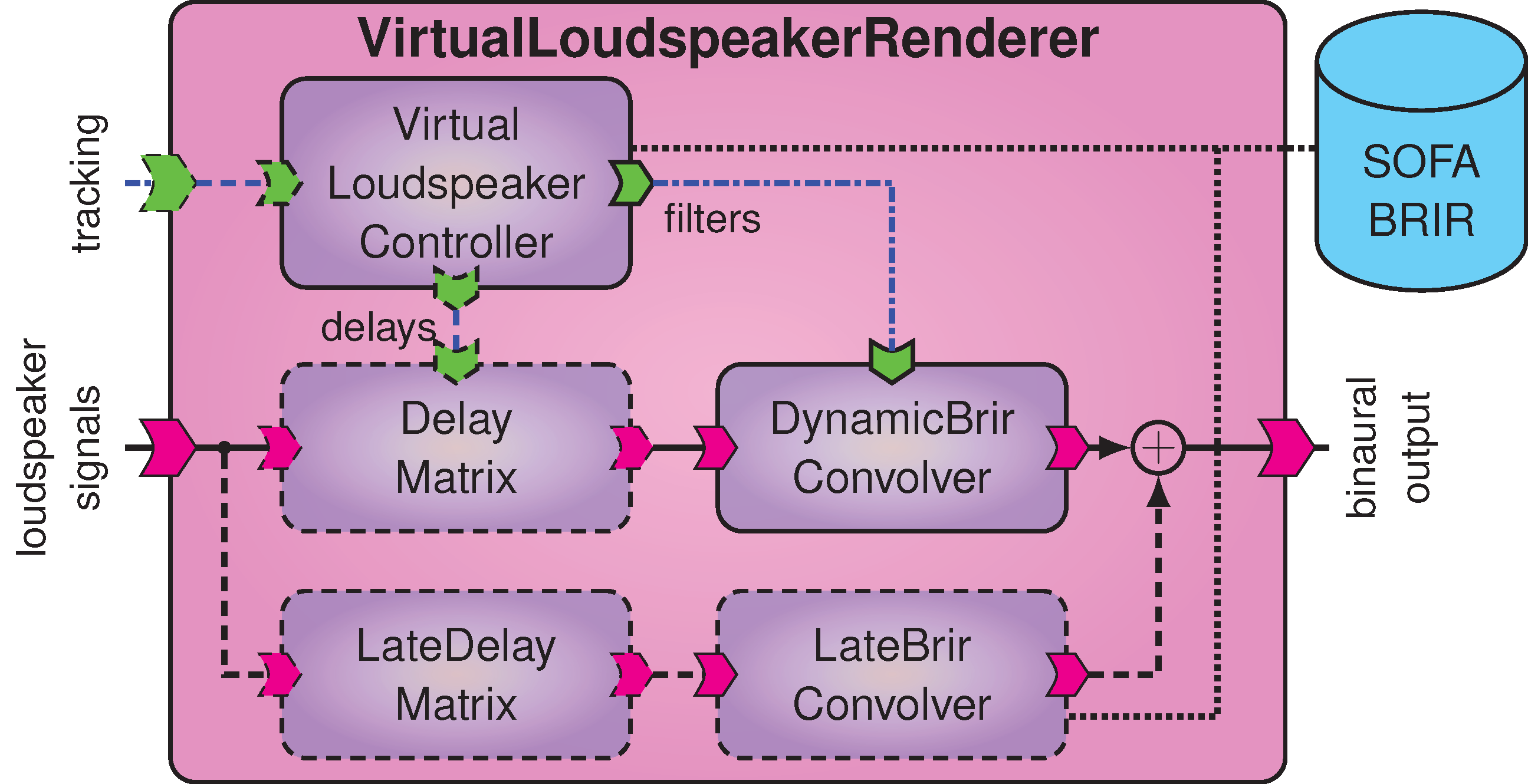
Virtual loudspeaker renderer.
The signal flow of the Virtual-Loudspeaker-Renderer is displayed Fig. Virtual loudspeaker renderer..
As in the dynamic HRIR renderer (Dynamic HRIR-Based Synthesis), the logic is implemented in a controller component, VirtualLoudspeakerController.
It loads the BRIR dataset from a SOFA file and uses the optional parameter input port tracking to select and potentially interpolate the room impulse responses according to the head rotation.
The resulting BRIRs are sent to the DynamicBrirConvolution component, where the \(L\) loudspeaker signals are convolved, optionally crossfaded, and summed to form the binaural output.
If the onset delays are extracted from the BRIRs, they are dynamically computed in the controller and applied in the optional DynamicDelayMatrix component.
As in case dynamic HRIR synthesis, this can help to improve filter interpolation, reduce switching artifacts, and allow for coarser BRIR datasets.
To reduce memory requirements and the computational load due to filter interpolation and switching, the late part of the BRIRs can optionally be rendered statically, i.e., independent of the head rotation, as described in [B21].
In this case, the loudspeaker signals are processed through an additional branch consisting of a fixed delay matrix LateDelayMatrix, which applies the time offset (mixing time) of the late reverberation tail, and the static convolver LateConvolutionEngine.
The result is combined with the dynamically convolved early part to form the binaural output signal.
Rendering Building Blocks¶
After describing the ready-made binaural synthesis approaches provided in the BST, this section explains the main DSP building blocks used to implement these algorithms in more detail. On the one hand, this is to provide more insight into the workings of these renderers. On the other hand, these components can also be used to adapt or extend the BST, or to implement alternative synthesis approaches.
As outlined in Sec. The VISR Framework, most of the present generic DSP functionality is implemented as C++ components in the VISR rcl library.
Python language interfaces are provided to enable their use in Python components.
They are typically application-independent and therefore highly configurable.
For instance, the widths (i.e., the number of individual signals) of input and output ports can be changed.
Other parameters, such as gains, delay values, or filters, can be either set statically or updated during runtime.
To this end, parameter ports to update these values can be activated in the component’s initialization, typically using an argument controlInputs with a component-specific enumeration type.
In a DelayVector object, for example, the setting controlInputs = rcl.DelayVector.PortConfigConfig.Delay activates the parameter input port to set delay values at runtime.
Convolution Kernels¶
Convolution with FIR filters representing HRIR or BRIR data is an essential operation in binaural synthesis. The VISR framework provides different components for multiple-input, multiple-output FIR filtering using fast convolution techniques.
The most basic, rcl.FirFilterMatrix, enables arbitrary sets of filtering operations between individual signals of its variable-width input and output ports.
To this end, so-called routings — lists of elements formed by an input index, an output index and a filter id — can be provided either during initialisation or at runtime.
In this way, widely different filtering operations can be performed by the same component.
Examples are multichannel channel-wise filtering, dense MIMO filter matrix, or application-specific topologies such as filtering a set of object signals to a left and right HRIR each, and summing the results ear-wise.
FFT and inverse FFT transforms are reused for multiple filtering operations where possible, improving efficiency compared to simple channel-wise convolution.
Depending on the configuration, both the routing points and the FIR filters can be exchanged at runtime, and the changes are performed instantaneously.
To avoid artifacts due to such filter switching operations, the component rcl.CrossFadingFirFilterMatrix extends this filter matrix by a crossfading implementation to enable smooth transitions.
To this end, an additional configuration parameter interpolationSteps is added to specify the duration of the transition to a new filter.
At the moment, this operation is performed in the time domain, thus incurring significant increase in computational complexity.
This can be partly alleviated by frequency-domain filter exchange strategies, e.g., [B24], which can be implemented
without changing the component’s interface.
Gain Vectors and Matrices¶
Gains are used, for example, to apply audio object levels or distance attenuation, or to perform matrix operations as rotations on HOA signals.
The VISR rcl library provides three component types for vector and matrix delays.
rcl.GainVector applies individual gains to an arbitrary-width audio signal.
rcl.GainMatrix performs a matrixing operation between an audio input and an audio output signal of arbitrary, possibly different widths using a dense matrix of gain coefficients.
If a significant part of the gains are zero, rcl.GainMatrixSparse performs this matrixing more efficiently.
To this end, rcl.GainMatrixSparse is configured with a set of routings, similar to those used with the convolution components, to describe the location of the nonzero gains.
All gain components can be configured with initial gains values to allow static operation with fixed coefficients.
Optionally, a parameter input gain can be activated to receive run-time updates.
In this case, the gains are smoothly and linearly changed to their new value within a transition period defined by the optional parameter interpolationSteps (in samples).
This ensures click-free operation.
Delay Lines: Vectors and Matrices¶
Time delays are ubiquitous in binaural synthesis, with uses ranging from modeling of propagation delays, simulation of Doppler effects, the separate application of HRIR/BRIR onset delays, or the incorporation of analytic ITD models.
The VISR provides two components, rcl.DelayVector and rcl.DelayMatrix for applying channel-wise and matrix time delays to arbitrary-width signals.
For time-variant delay operation, an optional parameter input delay is instantiated to receive runtime updates.
For artifact-free operation, the time delays are transitioned smoothly to the new values, based on a interpolationsteps configuration parameter as described above.
In addition, fractional delay (FD) filtering is essential for maintaining audio quality in time-variant delay lines.
To this end, a FD algorithm can be selected using the interpolationType parameter.
Currently the delay components support nearest-neighbor interpolation and Lagrange interpolation of arbitrary order based on an efficient linear-complexity implementation [B25].
Since signal delays are often applied in combination with a scaling, i.e., gain, and because these operations can be combined efficiently, the VISR delay components support an optional gain parameter input port that can be activated if required.
Head Tracking Data Receivers¶
For real-time dynamic rendering, data from head tracking devices must be supplied to the tracking input port.
To this end we provide an extensible library of tracking data receivers.
These are implemented in Python for conciseness and to make adaptation to other devices easier.
Tracking receiver components transform the device-specific tracking information into the parameter type pml.ListenerPosition that represents a listener position (not used in the current binaural renderers) and orientation within the VISR framework.
Currently, the following devices are supported: The following devices are supported at the moment.
Razor AHRS headtracker (https://github.com/Razor-AHRS/razor-9dof-ahrs), MrHeadTracker (https://git.iem.at/DIY/MrHeadTracker/), HTC VIVE Tracker (https://www.vive.com/us/vive-tracker/), and Intel RealSense (https://www.intel.com/content/www/us/en/architecture-and-technology/realsense-overview.html).
The separation of the tracking data receivers and the example implementations in Python will ease the creation of components for additional tracking devices.
Application Examples¶
In this section we provide a number of usage examples for the Binaural Synthesis Toolkit.
Offline algorithm evaluation¶
Algorithm development often requires deterministic, repeatable simulation runs and the generation of objective results such as waveforms, plots, or error metrics. The VISR Python integration provides an environment for simulating dynamic scenarios using the same binaural synthesis algorithms as in the real-time case in an offline, scripted fashion. To this end, one of the BST renderers (or an adapted version) is configured and instantiated in a Python script. Within this script, the renderer is executed in a block-by block fashion, providing audio object signals, object metadata and (optionally) listener orientation updates. The resulting binaural output signal can be displayed, saved as an audio file, or analyzed using the rich scientific computing libraries of Python. Thus it is easy to switch between conventional audio research and realtime rendering using the same code base.
Realtime HRIR synthesis of object-based scenes¶
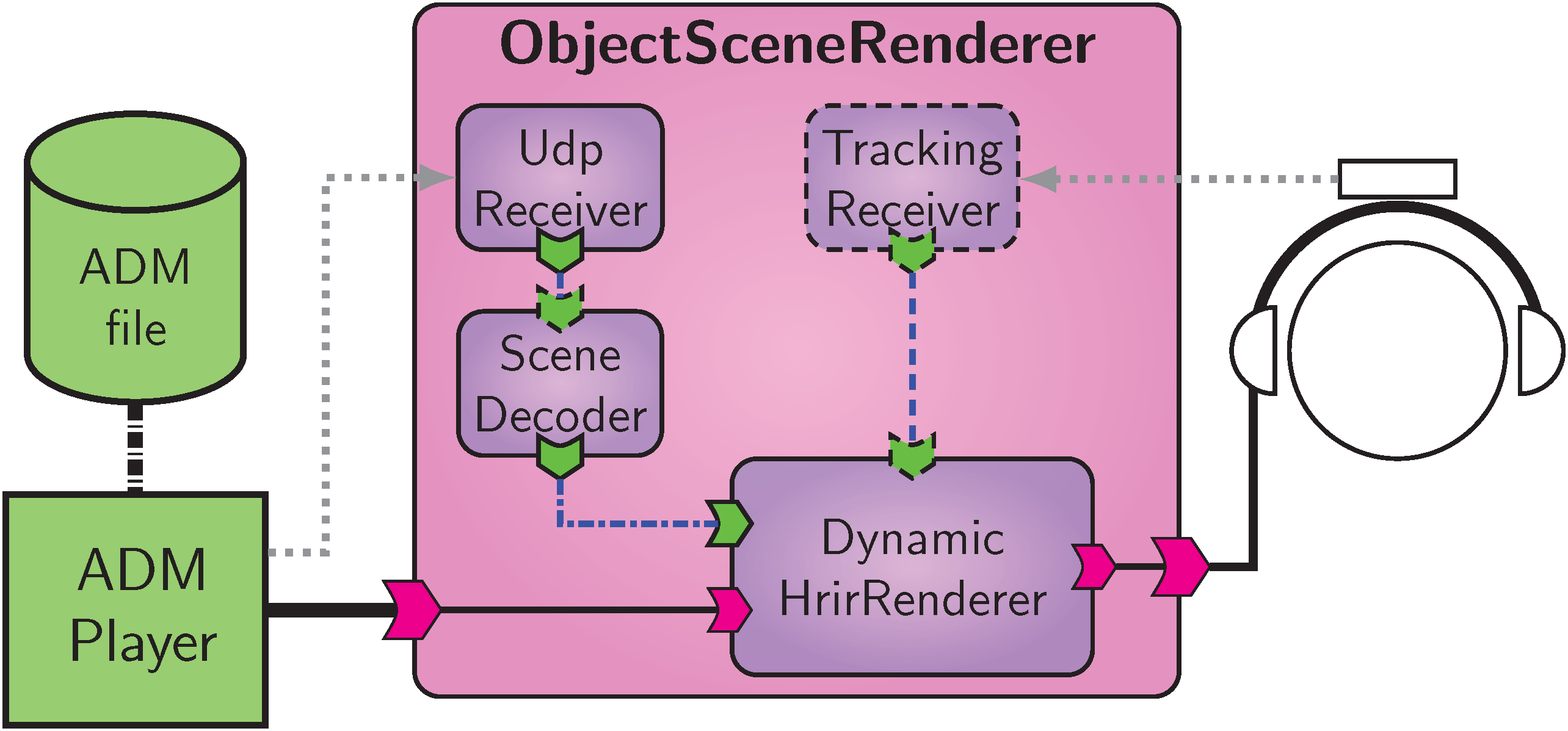
Application: Object scene rendering.
In this use case, a complex object-based scene, e.g., [B26] is reproduced binaurally.
The dynamic scene is stored in the Audio Definition Model (ADM) [B27] format and played through a specialized software player, generating a multichannel audio signal containing the object waveforms, and the object metadata as a UDP network stream.
A new composite component ObjectSceneRenderer, depicted in Fig. Application: Object scene rendering., is created to reproduce such content.
It contains a UdpReceiver and a SceneDecoder component, both part of the VISR rcl library, to receive object metadata and to decode it into the internal representation.
This and the multichannel object audio is passed to the DynamicHrirRenderer.
Optionally, information from a head tracking device is decoded in the HeadtrackingReceiver component and passed to the tracking input of the renderer.
Transaural Loudspeaker Array¶
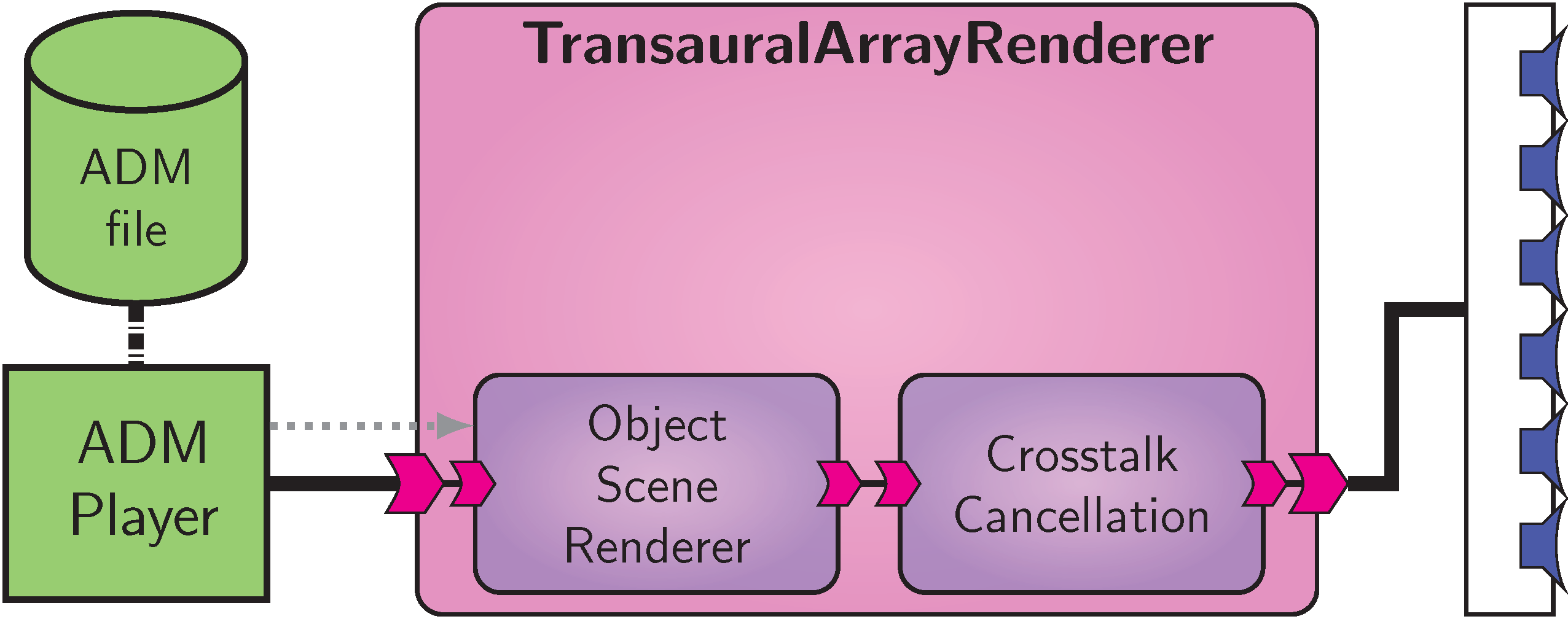
Application: Transaural array rendering
A variant of the object scene rendering for transaural array reproduction e.g., [B28] is depicted in Fig. Application: Transaural array rendering.
It features a new top-level composite component TransauralArrayRendering, which connects a ObjectSceneRenderer to the transaural-specific crosstalk cancellation algorithm, which is implemented using the VISR framework.
The output of the latter is sent to a multichannel loudspeaker array.
These examples show how the BST can be used in practical reproduction scenarios, and how it can be embedded in more complex audio algorithms.
Conclusion¶
In this paper we introduced the Binaural Synthesis Toolkit, an open, portable software package for binaural rendering over headphones and transaural systems. It features an extensible, component-based design that is based on the open VISR framework. Currently, the Binaural Synthesis Toolkit provides baseline implementations for three general binaural rendering schemes: Dynamic HRTF-based synthesis, rendering based on spherical higher order Ambisonics, and binaural room scanning. A distinguishing feature, compared to existing software, is the C++/Python interoperability of the BST and the underlying VISR framework. It facilitates accessible, readable code, ease of modification, and the ability to use the binaural rendering context in different applications or more complex processing systems.
While providing baseline rendering methods in an open, extensible toolkit will reamin the focus of the BST, future extensions might include a dynamic room model, listener position adaptation, or more sophisticated signal processing methods for convolution, filter interpolation and updating, or fractional delay filtering. We alsop aim to make the renderers and building available as easy-to use tools such as digital audio workstation (DAW) plugins or Max/MSP externals.
The intended use of the BST is as a tool for practical binaural sound reproduction and to foster reproducible research in audio.
References¶
| [B1] | Rozenn Nicol. Binaural Technology. AES Monographs. AES, New York, NY, 2010. |
| [B2] | Alexander Lindau and Stefan Weinzierl. Assessing the plausibility of virtual acoustic environments. Acta Acoustica United with Acoustica, 98(5):804–810, September 2012. |
| [B3] | (1, 2, 3) Jean-Marc Jot, Véronique Larcher, and Olivier Warusfel. Digital signal processing issues in the context of binaural and transaural stereophony. In Proc. Audio Eng. Soc. 98th Conv. Paris, France, February 1995. |
| [B4] | (1, 2, 3, 4) V. Ralph Algazi and Richard O.he Duda. Headphone-based spatial sound. IEEE Signal Processing Magazine, 28(1):33–42, January 2011. |
| [B5] | Chris Cannam, Lu’ıs Figueira, and Mark D. Plumbley. Sound software: towards software reuse in audio and music research. In Proc. IEEE Int. Conf. Acoust., Speech, Signal Process., 2745–2748. Kyoto, Japan, March 2012. |
| [B6] | Greg Wilson, D. A. Aruliah, C Brown, and others. Best practices for scientific computing. PLoS Biology, 12(1):e1001745, January 2014. |
| [B7] | (1, 2, 3, 4) Andreas Franck and Filippo Maria Fazi. VISR – a versatile open software framework for audio signal processing. In Proc. Audio Eng. Soc. 2018 Int. Conf. Spatial Reproduction. Tokyo, Japan, August 2018. |
| [B8] | (1, 2) Philip Mackensen, Uwe Felderhof, Günther Theile, and others. Binaural room scanning — a new tool for acoustic and psychoacoustic research. J. Acoust. Soc. Amer., 105(2):1343–1344, 1999. |
| [B9] | (1, 2) Jérôme Daniel, Jean-Bernard Rault, and Jean-Dominique Polack. Ambisonics encoding of other audio formats for multiple listening conditions. In Proc. Audio Eng. Soc. 105th Conv. San Francisco, CA, USA, September 1998. URL: http://www.aes.org/e-lib/browse.cfm?elib=8385. |
| [B10] | (1, 2) Audio Engineering Society. Aes69:2015 AES standard for file exchange – Spatial acoustic data file format. 2015. |
| [B11] | Matthias Geier and Sascha Spors. Spatial audio with the SoundScape renderer. In Proc. 27th Tonmeistertagung / VDT Int. Conv. Cologne, Germany, November 2012. |
| [B12] | Philip Coleman, Andreas Franck, Teofilo de Campos, and others. An audio-visual system for object-based audio: From recording to listening. IEEE Transactions on Multimedia, 2018. Accepted for publication. |
| [B13] | Travis E. Oliphant. Python for scientific computing. Computing in Science Engineering, 9(3):10–20, May 2007. |
| [B14] | (1, 2) Jean-Marc Jot, Adam Philp, and Martin Walsh. Binaural simulation of complex acoustic scenes for interactive audio. In Proc. Audio Eng. Soc. 121st Conv. San Francisco, CA, USA, October 2006. URL: http://www.aes.org/e-lib/browse.cfm?elib=13784. |
| [B15] | Hannes Gamper. Selection and interpolation of head-related transfer functions for rendering moving virtual sound sources. In Proc. 16th Int. Conf. Digital Audio Effects. Maynooth, Ireland, September 2013. |
| [B16] | Alexander Lindau, Jorgos Estrella, and Stefan Weinzierl. Individualization of dynamic binaural synthesis by real time manipulation of ITD. In Proc. Audio Eng. Soc. 128th Conv. London, UK, May 2010. URL: http://www.aes.org/e-lib/browse.cfm?elib=15385. |
| [B17] | Adam McKeag and David S. McGrath. Sound field format to binaural decoder with head tracking. In Proc. Audio Eng. Soc. 6th Australian Regional Conv. Melbourne, Australia, August 1996. URL: http://www.aes.org/e-lib/browse.cfm?elib=7477. |
| [B18] | Jean-Marc Jot, Scott Wardle, and Veronique Larcher. Approaches to binaural synthesis. In Proc. AES 105th Conv. San Francisco, CA, USA, September 1998. URL: http://www.aes.org/e-lib/browse.cfm?elib=8319. |
| [B19] | (1, 2) Benjamin Bernschutz, A. Vazquez Giner, C. Porschmann, and J. Arend. Binaural reproduction of plane waves with reduced modal order. Acta Acoustica United with Acoustica, 100(5):972–983, September 2014. URL: https://doi.org/10.3813/aaa.918777. |
| [B20] | Joseph Ivanic and Klaus Ruedenberg. Rotation matrices for real spherical harmonics. direct determination by recursion. J. Phys. Chem, 100(15):6342–6347, April 1996. |
| [B21] | (1, 2) Chris Pike, Frank Melchior, and Tony Tew. Assessing the plausibility of non-individualised dynamic binaural synthesis in a small room. In AES 55th Int. Conf. Spatial Audio. Helsinki, Finland, August 2014. |
| [B22] | Chris Pike and Michael Romanov. An impulse response dataset for dynamic data-based auralization of advanced sound systems. In Proc. Audio Eng. Soc. 142nd Conv. Berlin, Germany, May 2017. Engineering Brief. URL: http://www.aes.org/e-lib/browse.cfm?elib=18709. |
| [B23] | Mikko-Ville Laitinen and Ville Pulkki. Binaural reproduction for directional audio coding. In Proc. IEEE Workshop Applicat. Signal Process. Audio Acoust., 337–340. New Paltz, NY, October 2009. |
| [B24] | Andreas Franck. Efficient frequency-domain filter crossfading for fast convolution with application to binaural synthesis. In Proc. Audio Eng. Soc. 55th Int. Conf. Spatial Audio. Helsinki, Finland, August 2014. |
| [B25] | Andreas Franck. Efficient algorithms and structures for fractional delay filtering based on Lagrange interpolation. J. Audio Eng. Soc., 56(12):1036–1056, December 2008. |
| [B26] | James Woodcock, Chris Pike, Frank Melchior, and others. Presenting the s3a object-based audio drama dataset. In Proc. Audio Eng. Soc. 140th Conv. Paris, France, May 2016. Engineering Brief. URL: http://www.aes.org/e-lib/browse.cfm?elib=18159. |
| [B27] | ITU. Itu-r bs.2076-1 : audio definition model. 2017. |
| [B28] | Marcos Simón-Gálvez and Maria Fazi, Filippo. Loudspeaker arrays for transaural reproduction. In Proc. 22nd Int. Congr. Sound Vibration. Florence, Italy, July 2015. |
Component reference¶
The renderer components¶
The renderer classes contain the audio signal flow for one binaural synthesis approach. Typically, they have a large number of configuration parameters to select between different processing variants.
In contrasts to the realtime renderering components (Section Realtime rendering components), the core renderers are designed to be usable in very different environments, for example within a realtime renderer, but also in an offline simultation or a DAW external where control input is provided differently. For this reason, components as network data receivers are omitted, and all parameter input and output is handled through parameter ports instead.
Component DynamicHrirRenderer¶
DynamicHrirRenderer component
-
class
visr_bst.DynamicHrirRenderer(context, name, parent, numberOfObjects, *, sofaFile=None, hrirPositions=None, hrirData=None, hrirDelays=None, headOrientation=None, headTracking=True, dynamicITD=True, dynamicILD=True, hrirInterpolation=True, filterCrossfading=False, interpolatingConvolver=False, fftImplementation='default')¶ Rendering component for dynamic binaural synthesis based on HRTFs/HRIRs.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, holds the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- numberOfObjects (int) – Maximum number of audio objects
- sofaFile (str, optional) – Optional SOFA for loading loaded the HRIR and associated data (HRIR measurement positions and delays) If not provided, the information must be provided by the hrirPositions and hrirData arguments.
- hrirPositions (numpy.ndarray, optional) – Optional way to provide the measurement grid for the BRIR listener view directions. If a SOFA file is provided, this is optional and overrides the listener view data in the file. Otherwise this argument is mandatory. Dimension #grid directions x (dimension of position argument)
- hrirData (numpy.ndarray, optional) – Optional way to provide the BRIR data. Dimension: #grid directions x #ears (2) # x #loudspeakers x #ir length
- hrirDelays (numpy.ndarray, optional) – Optional BRIR delays. If a SOFA file is given, this argument overrides a potential delay setting from the file. Otherwise, no extra delays are applied unless this option is provided. Dimension: #grid directions x #ears(2) x # loudspeakers
- headOrientation (array-like, optional) – Head orientation in spherical coordinates (2- or 3-element vector or list). Either a static orientation (when no tracking is used), or the initial view direction
- headTracking (bool) – Whether dynamic head tracking is supported. If True, a parameter input with type pml.ListenerPosition and protocol pml.DoubleBufffering is created.
- dynamicITD (bool, optional) – Whether the ITD is applied separately. That requires preprocessed HRIR data
- dynamicILD (bool, optional) – Whether the ILD is computed and applied separately. At the moment this feature is not used (apart from applying the object gains)
- hrirInterpolation (bool, optional) – Whether the controller supports interpolation between neighbouring HRTF grid points. False means nearest neighbour (no interpolation), True enables barycentric interpolation.
- filterCrossfading (bool, optional) – Use a crossfading FIR filter matrix to avoid switching artifacts.
- fftImplementation (string, optional) – The FFT implementation to use. Default value enables VISR’s default FFT library for the platform.
Component HoaBinauralRenderer¶
-
class
visr_bst.HoaBinauralRenderer(context, name, parent, hoaOrder=None, sofaFile=None, decodingFilters=None, interpolationSteps=None, headOrientation=None, headTracking=True, fftImplementation='default')¶ Component to render binaural audio from plane wave and point source objects using an Higher Order Ambisonics (HOA) algorithm.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, holds the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- hoaOrder (int or None) – The maximum HOA order that can be reproduced. If None, the HOA order is deduced from the first dimension of the HOA filters (possibly contained in a SOFA file).
- sofaFile (string or NoneType) – A file in SOFA format containing the decoding filters. This expects the filters in the field ‘Data.IR’, dimensions (hoaOrder+1)**2 x 2 x irLength. If None, then the filters must be provided in ‘decodingFilters’ parameter.
- decodingFilters (numpy.ndarray or NoneType) – Alternative way to provide the HOA decoding filters.
- interpolationSteps (int, optional) – Number of samples to transition to new object positions after an update.
- headOrientation (array-like) – Head orientation in spherical coordinates (2- or 3-element vector or list). Either a static orientation (when no tracking is used), or the initial view direction
- headTracking (bool) – Whether dynamic head tracking is active.
- fftImplementation (string, optional) – The FFT library to be used in the filtering. THe default uses VISR’s default implementation for the present platform.
Component HoaObjectToBinauralRenderer¶
-
class
visr_bst.HoaObjectToBinauralRenderer(context, name, parent, numberOfObjects, maxHoaOrder=None, sofaFile=None, decodingFilters=None, interpolationSteps=None, headOrientation=None, headTracking=True, objectChannelAllocation=False, fftImplementation='default')¶ Component to render binaural audio from plane wave and point source objects using an Higher Order Ambisonics (HOA) algorithm.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, holds the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- numberOfObjects (int) – The number of audio objects to be rendered.
- maxHoaOrder (int or None) – The maximum HOA order that can be reproduced. If None, the HOA order is deduced from the first dimension of the HOA filters (possibly contained in a SOFA file).
- sofaFile (string or NoneType) –
- decodingFilters (numpy.ndarray or NoneType) – Alternative way to provide the HOA decoding filters.
- interpolationSteps (int) –
- headOrientation (array-like) – Head orientation in spherical coordinates (2- or 3-element vector or list). Either a static orientation (when no tracking is used), or the initial view direction
- headTracking (bool) – Whether dynamic head tracking is active.
- objectChannelAllocation (bool) – Whether the processing resources are allocated from a pool of resources (True), or whether fixed processing resources statically tied to the audio signal channels are used. Not implemented at the moment, so leave the default value (False).
- fftImplementation (string, optional) – The FFT library to be used in the filtering. THe default uses VISR’s default implementation for the present platform.
Component VirtualLoudspeakerRenderer¶
-
class
visr_bst.VirtualLoudspeakerRenderer(context, name, parent, *, sofaFile=None, hrirPositions=None, hrirData=None, hrirDelays=None, headOrientation=None, headTracking=True, dynamicITD=False, hrirInterpolation=False, irTruncationLength=None, filterCrossfading=False, interpolatingConvolver=False, staticLateSofaFile=None, staticLateFilters=None, staticLateDelays=None, fftImplementation='default')¶ Signal flow for rendering binaural output for a multichannel signal reproduced over a virtual loudspeaker array with corresponding BRIR data.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, a structure holding the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- sofaFile (string) – BRIR database provided as a SOFA file. This is an alternative to the hrirPosition, hrirData (and optionally hrirDelays) argument. Default None means that hrirData and hrirPosition must be provided.
- hrirPositions (numpy.ndarray) – Optional way to provide the measurement grid for the BRIR listener view directions. If a SOFA file is provided, this is optional and overrides the listener view data in the file. Otherwise this argument is mandatory. Dimension #grid directions x (dimension of position argument)
- hrirData (numpy.ndarray) – Optional way to provide the BRIR data. Dimension: #grid directions x #ears (2) # x #loudspeakers x #ir length
- hrirDelays (numpy.ndarray) – Optional BRIR delays. If a SOFA file is given, this argument overrides a potential delay setting from the file. Otherwise, no extra delays are applied unless this option is provided. Dimension: #grid directions x #ears(2) x # loudspeakers
- headOrientation (array-like) – Head orientation in spherical coordinates (2- or 3-element vector or list). Either a static orientation (when no tracking is used), or the initial view direction
- headTracking (bool) – Whether dynamic headTracking is active. If True, an control input “tracking” is created.
- dynamicITD (bool) – Whether the delay part of th BRIRs is applied separately to the (delay-free) BRIRs.
- hrirInterpolation (bool) – Whether BRIRs are interpolated for the current head oriention. If False, a nearest-neighbour interpolation is used.
- irTruncationLength (int) – Maximum number of samples of the BRIR impulse responses. Functional only if the BRIR is provided in a SOFA file.
- filterCrossfading (bool) – Whether dynamic BRIR changes are crossfaded (True) or switched immediately (False)
- interpolatingConvolver (bool) – Whether the interpolating convolver option is used. If True, the convolver stores all BRIR filters, and the controller sends only interpolation coefficient messages to select the BRIR filters and their interpolation ratios.
- staticLateSofaFile (string, optional) – Name of a file containing a static (i.e., head orientation-independent) late part of the BRIRs. Optional argument, might be used as an alternative to the staticLateFilters argument, but these options are mutually exclusive. If neither is given, no static late part is used. The fields ‘Data.IR’ and the ‘Data.Delay’ are used.
- staticLateFilters (numpy.ndarray, optional) – Matrix containing a static, head position-independent part of the BRIRs. This option is mutually exclusive to staticLateSofaFile. If none of these is given, no separate static late part is rendered. Dimension: 2 x #numberOfLoudspeakers x firLength
- staticLateDelays (numpy.ndarray, optional) – Time delay of the late static BRIRs per loudspeaker. Optional attribute, only used if late static BRIR coefficients are provided. Dimension: 2 x #loudspeakers
- fftImplementation (string) – The FFT implementation to be used in the convolver. the default value selects the system default.
Component ObjectToVirtualLoudspeakerRenderer¶
-
class
visr_bst.ObjectToVirtualLoudspeakerRenderer(context, name, parent, *, numberOfObjects, sofaFile=None, hrirPositions=None, hrirData=None, hrirDelays=None, headOrientation=None, headTracking=True, dynamicITD=False, hrirInterpolation=False, irTruncationLength=None, filterCrossfading=False, interpolatingConvolver=False, staticLateSofaFile=None, staticLateFilters=None, staticLateDelays=None, fftImplementation='default', loudspeakerConfiguration=None, loudspeakerRouting=None, objectRendererOptions={})¶ Signal flow for rendering an object-based scene over a virtual loudspeaker binaural renderer.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, a structure holding the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- sofaFile (string) – BRIR database provided as a SOFA file. This is an alternative to the hrirPosition, hrirData (and optionally hrirDelays) argument. Default None means that hrirData and hrirPosition must be provided.
- hrirPositions (numpy.ndarray) – Optional way to provide the measurement grid for the BRIR listener view directions. If a SOFA file is provided, this is optional and overrides the listener view data in the file. Otherwise this argument is mandatory. Dimension #grid directions x (dimension of position argument)
- hrirData (numpy.ndarray) – Optional way to provide the BRIR data. Dimension: #grid directions x #ears (2) # x #loudspeakers x #ir length
- hrirDelays (numpy.ndarray) – Optional BRIR delays. If a SOFA file is given, this argument overrides a potential delay setting from the file. Otherwise, no extra delays are applied unless this option is provided. Dimension: #grid directions x #ears(2) x # loudspeakers
- headOrientation (array-like) – Head orientation in spherical coordinates (2- or 3-element vector or list). Either a static orientation (when no tracking is used), or the initial view direction
- headTracking (bool) – Whether dynamic headTracking is active. If True, an control input “tracking” is created.
- dynamicITD (bool) – Whether the delay part of th BRIRs is applied separately to the (delay-free) BRIRs.
- hrirInterpolation (bool) – Whether BRIRs are interpolated for the current head oriention. If False, a nearest-neighbour interpolation is used.
- irTruncationLength (int) – Maximum number of samples of the BRIR impulse responses. Functional only if the BRIR is provided in a SOFA file.
- filterCrossfading (bool) – Whether dynamic BRIR changes are crossfaded (True) or switched immediately (False)
- interpolatingConvolver (bool) – Whether the interpolating convolver option is used. If True, the convolver stores all BRIR filters, and the controller sends only interpolation coefficient messages to select the BRIR filters and their interpolation ratios.
- staticLateSofaFile (string, optional) – Name of a file containing a static (i.e., head orientation-independent) late part of the BRIRs. Optional argument, might be used as an alternative to the staticLateFilters argument, but these options are mutually exclusive. If neither is given, no static late part is used. The fields ‘Data.IR’ and the ‘Data.Delay’ are used.
- staticLateFilters (numpy.ndarray, optional) – Matrix containing a static, head position-independent part of the BRIRs. This option is mutually exclusive to staticLateSofaFile. If none of these is given, no separate static late part is rendered. Dimension: 2 x #numberOfLoudspeakers x firLength
- staticLateDelays (numpy.ndarray, optional) – Time delay of the late static BRIRs per loudspeaker. Optional attribute, only used if late static BRIR coefficients are provided. Dimension: 2 x #loudspeakers
- fftImplementation (string) – The FFT implementation to be used in the convolver. the default value selects the system default.
- loudspeakerConfiguration (panning.LoudspeakerArray) – Loudspeaker configuration object used in the ob ject renderer. Must not be None
- loudspeakerRouting (array-like list of integers or None) – Routing indices from the outputs of the object renderer to the inputs of the binaural virtual loudspeaker renderer. If empty, the outputs of the object renderer are connected to the first inputs of the virt. lsp renderer.
- objectRendererOptions (dict) – Keyword arguments passed to the object renderer (rcl.CoreRenderer). This may involve all optional arguments for this class apart from loudspeakerConfiguration, numberOfInputs, and numberOfOutputs. If provided, these paremters are overwritten by the values determined from the binaural renderer’s configuration.
Realtime rendering components¶
The realtime rendering components provide signal flows for the different rendering approaches including the realtime input/output for head tracking information and, where applicable, object metadata. These classes are therefore less versatile than the core renderers described in Section The renderer components, but provide ready-to-go components for many practical uses.
Component RealtimeDynamicHrirRenderer¶
-
class
visr_bst.RealtimeDynamicHrirRenderer(context, name, parent, *, numberOfObjects, sofaFile=None, hrirPositions=None, hrirData=None, hrirDelays=None, headOrientation=None, dynamicITD=False, dynamicILD=False, hrirInterpolation=False, filterCrossfading=False, fftImplementation='default', headTrackingReceiver=None, headTrackingPositionalArguments=None, headTrackingKeywordArguments=None, sceneReceiveUdpPort=None)¶ VISR component for realtime audio rendering of object-based scenes using a ‘dynamic HRIR’ approach.
It contains a DynamicHrirRenderer component, but optionally adds a receiver component for head tracking devices and real-time receipt of object metadata from UDP network packets.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, holds the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- numberOfObjects (int) – Maximum number of audio objects
- sofaFile (str, optional) – Optional SOFA for loading loaded the HRIR and associated data (HRIR measurement positions and delays) If not provided, the information must be provided by the hrirPositions and hrirData arguments.
- hrirPositions (numpy.ndarray, optional) – Optional way to provide the measurement grid for the BRIR listener view directions. If a SOFA file is provided, this is optional and overrides the listener view data in the file. Otherwise this argument is mandatory. Dimension #grid directions x (dimension of position argument)
- hrirData (numpy.ndarray, optional) – Optional way to provide the BRIR data. Dimension: #grid directions x #ears (2) # x #loudspeakers x #ir length
- hrirDelays (numpy.ndarray, optional) – Optional BRIR delays. If a SOFA file is given, this argument overrides a potential delay setting from the file. Otherwise, no extra delays are applied unless this option is provided. Dimension: #grid directions x #ears(2) x # loudspeakers
- headOrientation (array-like, optional) – Head orientation in spherical coordinates (2- or 3-element vector or list). Either a static orientation (when no tracking is used), or the initial view direction
- dynamicITD (bool, optional) – Whether the ITD is applied separately. That requires preprocessed HRIR data
- dynamicILD (bool, optional) – Whether the ILD is computed and applied separately. At the moment this feature is not used (apart from applying the object gains)
- hrirInterpolation (bool, optional) – Whether the controller supports interpolation between neighbouring HRTF grid points. False means nearest neighbour (no interpolation), True enables barycentric interpolation.
- filterCrossfading (bool, optional) – Use a crossfading FIR filter matrix to avoid switching artifacts.
- fftImplementation (string, optional) – The FFT implementation to use. Default value enables VISR’s default FFT library for the platform.
- headTrackingReceiver (class type, optional) – Class of the head tracking recveiver, None (default value) disables dynamic head tracking.
- headTrackingPositionalArguments (tuple optional) – Positional arguments passed to the constructor of the head tracking receiver object. Must be a tuple. If there is only a single argument, a trailing comma must be added.
- headTrackingKeywordArguments (dict, optional) – Keyword arguments passed to the constructor of the head tracking receiver. Must be a dictionary (dict)
- sceneReceiveUdpPort (int, optional) – A UDP port number where scene object metadata (in the S3A JSON format) is to be received). If not given (default), no network receiver is instantiated, and the object exposes a top-level parameter input port “objectVectorInput”
Component RealtimeHoaObjectToBinauralRenderer¶
-
class
visr_bst.RealtimeHoaObjectToBinauralRenderer(context, name, parent, *, numberOfObjects, maxHoaOrder, sofaFile=None, decodingFilters=None, interpolationSteps=None, headTracking=True, headOrientation=None, objectChannelAllocation=False, fftImplementation='default', headTrackingReceiver=None, headTrackingPositionalArguments=None, headTrackingKeywordArguments=None, sceneReceiveUdpPort=None)¶ VISR component for realtime audio rendering of object-based scenes using a Higher-order Ambisonics encoding of point source/plane wave objects and binaural rendering of the soiundfield representation.
It contains a HoaObjectToRenderer component, but optionally adds a receiver component for head tracking devices and real-time receipt of object metadata from UDP network packets.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, holds the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- numberOfObjects (int) – The number of audio objects to be rendered.
- maxHoaOrder (int) – HOA order used for encoding the point source and plane wave objects.
- sofaFile (string, optional) – A SOFA file containing the HOA decoding filters. These are expects as a 2 x (maxHoaIrder+1)^2 array in the field Data.IR
- decodingFilters (numpy.ndarray, optional) – Alternative way to provide the HOA decoding filters. Expects a 2 x (maxHoaIrder+1)^2 matrix containing FIR coefficients.
- interpolationSteps (int, optional) – Number of samples to transition to new object positions after an update.
- headOrientation (array-like) – Head orientation in spherical coordinates (2- or 3-element vector or list). Either a static orientation (when no tracking is used), or the initial view direction
- headTracking (bool) – Whether dynamic head tracking is active.
- objectChannelAllocation (bool) – Whether the processing resources are allocated from a pool of resources (True), or whether fixed processing resources statically tied to the audio signal channels are used. Not implemented at the moment, so leave the default value (False).
- fftImplementation (string, optional) – The FFT implementation to use. Default value enables VISR’s default FFT library for the platform.
- headTrackingReceiver (class type, optional) – Class of the head tracking recveiver, None (default value) disables dynamic head tracking.
- headTrackingPositionalArguments (tuple optional) – Positional arguments passed to the constructor of the head tracking receiver object. Must be a tuple. If there is only a single argument, a trailing comma must be added.
- headTrackingKeywordArguments (dict, optional) – Keyword arguments passed to the constructor of the head tracking receiver. Must be a dictionary (dict)
- sceneReceiveUdpPort (int, optional) – A UDP port number where scene object metadata (in the S3A JSON format) is to be received). If not given (default), no network receiver is instantiated, and the object exposes a top-level parameter input port “objectVectorInput”
Component RealtimeHoaBinauralRenderer¶
-
class
visr_bst.RealtimeHoaBinauralRenderer(context, name, parent, *, hoaOrder=None, sofaFile=None, decodingFilters=None, interpolationSteps=None, headTracking=True, headOrientation=None, fftImplementation='default', headTrackingReceiver=None, headTrackingPositionalArguments=None, headTrackingKeywordArguments=None)¶ VISR component for realtime audio rendering of Higher-order Ambisonics (HOA) audio.
It contains a HoaObjectToRenderer component, but optionally adds a receiver component for head tracking devices
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, holds the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- hoaOrder (optional, int or None) – HOA order used for encoding the point source and plane wave objects. If not provided, the order is determined from the number of decoding filters (either passed as a matrix or in a SOFA file)
- sofaFile (string, optional) – A SOFA file containing the HOA decoding filters. These are expects as a 2 x (maxHoaIrder+1)^2 array in the field Data.IR
- decodingFilters (numpy.ndarray, optional) – Alternative way to provide the HOA decoding filters. Expects a 2 x (maxHoaIrder+1)^2 matrix containing FIR coefficients.
- interpolationSteps (int, optional) – Number of samples to transition to new object positions after an update.
- headOrientation (array-like) – Head orientation in spherical coordinates (2- or 3-element vector or list). Either a static orientation (when no tracking is used), or the initial view direction
- headTracking (bool) – Whether dynamic head tracking is active.
- fftImplementation (string, optional) – The FFT implementation to use. Default value enables VISR’s default FFT library for the platform.
- headTrackingReceiver (class type, optional) – Class of the head tracking recveiver, None (default value) disables dynamic head tracking.
- headTrackingPositionalArguments (tuple optional) – Positional arguments passed to the constructor of the head tracking receiver object. Must be a tuple. If there is only a single argument, a trailing comma must be added.
- headTrackingKeywordArguments (dict, optional) – Keyword arguments passed to the constructor of the head tracking receiver. Must be a dictionary (dict)
Component RealtimeVirtualLoudspeakerRenderer¶
-
class
visr_bst.RealtimeVirtualLoudspeakerRenderer(context, name, parent, *, sofaFile=None, hrirPositions=None, hrirData=None, hrirDelays=None, headOrientation=None, dynamicITD=True, hrirInterpolation=True, irTruncationLength=None, filterCrossfading=False, interpolatingConvolver=False, staticLateSofaFile=None, staticLateFilters=None, staticLateDelays=None, headTrackingReceiver=None, headTrackingPositionalArguments=None, headTrackingKeywordArguments=None, fftImplementation='default')¶ Binaural renderer to transform a set of loudspeaker signals into a binaural output.
This class extends visr_bst.VirtualLoudspeakerRenderer by a configurable head tracking receiver, making it suitable for realtime use.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, a structure holding the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- sofaFile (string) – BRIR database provided as a SOFA file. This is an alternative to the hrirPosition, hrirData (and optionally hrirDelays) argument. Default None means that hrirData and hrirPosition must be provided.
- hrirPositions (numpy.ndarray) – Optional way to provide the measurement grid for the BRIR listener view directions. If a SOFA file is provided, this is optional and overrides the listener view data in the file. Otherwise this argument is mandatory. Dimension #grid directions x (dimension of position argument)
- hrirData (numpy.ndarray) – Optional way to provide the BRIR data. Dimension: #grid directions x #ears (2) # x #loudspeakers x #ir length
- hrirDelays (numpy.ndarray) – Optional BRIR delays. If a SOFA file is given, this argument overrides a potential delay setting from the file. Otherwise, no extra delays are applied unless this option is provided. Dimension: #grid directions x #ears(2) x # loudspeakers
- headOrientation (array-like) – Head orientation in spherical coordinates (2- or 3-element vector or list). Either a static orientation (when no tracking is used), or the initial view direction
- headTracking (bool) – Whether dynamic headTracking is active. If True, an control input “tracking” is created.
- dynamicITD (bool) – Whether the delay part of th BRIRs is applied separately to the (delay-free) BRIRs.
- hrirInterpolation (bool) – Whether BRIRs are interpolated for the current head oriention. If False, a nearest-neighbour interpolation is used.
- irTruncationLength (int) – Maximum number of samples of the BRIR impulse responses. Functional only if the BRIR is provided in a SOFA file.
- filterCrossfading (bool) – Whether dynamic BRIR changes are crossfaded (True) or switched immediately (False)
- interpolatingConvolver (bool) – Whether the interpolating convolver option is used. If True, the convolver stores all BRIR filters, and the controller sends only interpolation coefficient messages to select the BRIR filters and their interpolation ratios.
- staticLateSofaFile (string, optional) – Name of a file containing a static (i.e., head orientation-independent) late part of the BRIRs. Optional argument, might be used as an alternative to the staticLateFilters argument, but these options are mutually exclusive. If neither is given, no static late part is used. The fields ‘Data.IR’ and the ‘Data.Delay’ are used.
- staticLateFilters (numpy.ndarray, optional) – Matrix containing a static, head position-independent part of the BRIRs. This option is mutually exclusive to staticLateSofaFile. If none of these is given, no separate static late part is rendered. Dimension: 2 x #numberOfLoudspeakers x firLength
- staticLateDelays (numpy.ndarray, optional) – Time delay of the late static BRIRs per loudspeaker. Optional attribute, only used if late static BRIR coefficients are provided. Dimension: 2 x #loudspeakers
- fftImplementation (string) – The FFT implementation to be used in the convolver. the default value selects the system default.
Controller components¶
Controller components implement the logic of binaural synthesis renderer and control the audio processing. Therefore the form the core of the BST. There are two controllers, one for dynamic HRIR synthesis and one for virtual loudspeaker rendererin. Note that the HOA synthesis rendering does not require a controller.
Component DynamicHrirController¶
-
class
visr_bst.DynamicHrirController(context, name, parent, numberOfObjects, hrirPositions, hrirData, headRadius=0.0875, useHeadTracking=False, dynamicITD=False, dynamicILD=False, interpolatingConvolver=False, hrirInterpolation=False, channelAllocation=False, hrirDelays=None)¶ Component to translate an object vector (and optionally head tracking information) into control parameter for dynamic binaural signal processing.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, a structure holding the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- numberOfObjects (int) – The number of point source objects rendered.
- hrirPositions (numpy.ndaarray) – The directions of the HRTF measurements, given as a Nx3 array
- hrirData (numpy.ndarray) – The HRTF data as 3 Nx2xL matrix, with L as the FIR length.
- headRadius (float) – Head radius, optional and not currently used. Might be used in a dynamic ITD/ILD individualisation algorithm.
- useHeadTracking (bool) – Whether head tracking data is provided via a self.headOrientation port.
- dynamicITD (bool) – Whether ITD delays are calculated and sent via a “delays” port.
- dynamicILD (bool) – Whether ILD gains are calculated and sent via a “gains” port.
- hrirInterpolation (bool) – HRTF interpolation selection: False: Nearest neighbour, True: Barycentric (3-point) interpolation
- channelAllocation (bool) – Whether to allocate object channels dynamically (not tested yet)
- hrirDelays (numpy.ndarray) – Matrix of delays associated with filter dataset. Dimension: # filters * 2. Default None means there are no separate delays, i.e., they must be contained in the HRIR data.
Component VirtualLoudspeakerController¶
-
class
visr_bst.VirtualLoudspeakerController(context, name, parent, *, hrirPositions, hrirData, headOrientation=None, headTracking=False, dynamicITD=False, hrirInterpolation=False, hrirDelays=None, interpolatingConvolver=False)¶ Controller component for a dynamic (head-tracked) virtual loudspeaker (or binaural room scanning) renderer.
Computes and sends control paramters to the DSP components of a virtual loudspeaker renderer.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, a structure holding the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- hrirPositions (numpy.ndarray) – Optional way to provide the measurement grid for the BRIR listener view directions. If a SOFA file is provided, this is optional and overrides the listener view data in the file. Otherwise this argument is mandatory. Dimension #grid directions x (dimension of position argument)
- hrirData (numpy.ndarray) – Optional way to provide the BRIR data. Dimension: #grid directions x #ears (2) # x #loudspeakers x #ir length
- headOrientation (array-like) – Head orientation in spherical coordinates (2- or 3-element vector or list). Either a static orientation (when no tracking is used), or the initial view direction
- headTracking (bool) – Whether dynamic headTracking is active. If True, an control input “tracking” is created.
- dynamicITD (bool) – Whether the delay part of th BRIRs is applied separately to the (delay-free) BRIRs.
- hrirInterpolation (bool) – Whether BRIRs are interpolated for the current head oriention. If False, a nearest-neighbour interpolation is used.
- hrirDelays (numpy.ndarray) – Optional BRIR delays. If a SOFA file is given, this argument overrides a potential delay setting from the file. Otherwise, no extra delays are applied unless this option is provided. Dimension: #grid directions x #ears(2) x # loudspeakers
- interpolatingConvolver (bool) – Whether the interpolating convolver option is used. If True, the convolver stores all BRIR filters, and the controller sends only interpolation coefficient messages to select the BRIR filters and their interpolation ratios.
HOA components¶
The sub-module visr_bst.hoa_components contains a set of processing components that are used
in the HOA (higher-order Ambisonics) binaural rendering approaches.
Note
These classes might be moved outside the visr_bst module in the future, and might also be reimplemented in C++.
Component HoaObjectEncoder¶
-
class
visr_bst.hoa_components.HoaObjectEncoder(context, name, parent, numberOfObjects, hoaOrder, channelAllocation=False)¶ Component to calculate encoding coefficients for point source and plane wave audio objects contained in an object vector.
Constructor.
Parameters: - numberOfObjects (int) – The maximum number of audio objects to be rendered.
- hoaOrder (int) – The Ambisonics order for encoding the objects.
- channelAllocation (bool, optional) – Whether to send dynamic channel allocation data. Not used at the moment. Default value means that the object channels are allocated statically and correspond to the obbject’s channel id.
Component HoaCoefficientRotation¶
-
class
visr_bst.hoa_components.HoaCoefficientRotation(context, name, parent, numberOfObjects, hoaOrder, dynamicUpdates=False, headOrientation=None)¶ Component to apply a rotation to a matrix of spherical harmonic coefficients.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Structure containing block size and sampling frequency, standard visr component construction parameter.
- name (string) – Name of the component, can be chosen freely as long as it is unique withion the containing component.
- parent (visr.CompositeComponent or NoneType) – The containing composite component, or None for a top-level component.
- numberOfObjects (int) – The number of objects to be rendered, i.e., columns in the received spherical harmonics matrices.
- hoaOrder (int) – The order of the spherical harmonics. Defines the number of rows of the processed matrices ((hoaOrder+1)^2)
- headOrientation (array-like (2- or 3- element) or NoneType) – The initial head rotation or the static head orientation if dynamic updates are deactivated. Given as yaw, pitch, roll.
Component HoaRotationMatrixCalculator¶
-
class
visr_bst.hoa_components.HoaRotationMatrixCalculator(context, name, parent, hoaOrder, dynamicOrientation=False, initialOrientation=None)¶ Component to compute a spherical harmonics rotation matrix. The matrix coeffients are output as a coefficient list for a sparse matrix.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Structure containing block size and sampling frequency, standard visr component construction parameter.
- name (string) – Name of the component, can be chosen freely as long as it is unique withion the containing component.
- parent (visr.CompositeComponent or NoneType) – The containing composite component, or None for a top-level component.
- hoaOrder (int) – The spherical harmonics order, determines the size of the output matrix.
- dynamicOrientation (bool) – Whether the orientation is updated at runtime. If True, a parmater input “orientation” is instantiated that receivers pml.ListenerPositions
- initialOrientation (array-like (2- or 3- element) or NoneType) – The initial head rotation or the static head orientation if dynamic updates are deactivated. Given as yaw, pitch, roll.
Trackers¶
Tracker classes receive data from headtracking devices and create pml.ListenerPosition parameters.
Tracker objects can be used either in custom signal flows or passed as optional arguments to the Realtime rendering components.
Component RazorAHRS¶
-
class
visr_bst.tracker.RazorAHRS(context, name, parent, port, yawOffset=0, pitchOffset=0, rollOffset=0, yawRightHand=False, pitchRightHand=False, rollRightHand=False, calibrationInput=False)¶ Component to receive tracking data from a Razor AHRS device through a serial port.
Constructor.
Parameters: - context (visr.SignalFlowContext) – Standard visr.Component construction argument, a structure holding the block size and the sampling frequency
- name (string) – Name of the component, Standard visr.Component construction argument
- parent (visr.CompositeComponent) – Containing component if there is one, None if this is a top-level component of the signal flow.
- yawOffset – Initial offset for the yaw component, default 0.0
- pitchOffset (float) – Offset for the pitch value, in degree
- rollOffset (float:) – Initial value for the roll component, default 0.0
- yawRightHand (bool) – Whehther the yaw coordinate is interpreted as right-hand (mathematically negative) rotation. Default: False
- pitchRightHand (bool) – Whehther the pitch coordinate is interpreted as right-hand (mathematically negative) rotation. Default: False
- rollRightHand (bool) – Whehther the roll coordinate is interpreted as right-hand (mathematically negative) rotation. Default: False
- calibrationInput (bool) – Flag to determine whehter the component has an additional input “calibration” that resets the orientation offsets. At the moment, this input is of type StringParameter, and the value is ignored.
- TODO (Check whether to support ListenerPosition objects as calibration triggers) –
- set the orientation to an arbitrary value (to) –
Component RazorAHRSWithUdpCalibrationTrigger¶
-
class
visr_bst.tracker.RazorAHRSWithUdpCalibrationTrigger(context, name, parent, *, calibrationPort, **razorArgs)¶ Receiver for the Razor AHRS head tracker with an additional UDP receiver port for calibration, i.e., to define the current look direction as the ‘zero’, frontal orientation.
Constructor.
- context : visr.SignalFlowContext
- Standard visr.Component construction argument, a structure holding the block size and the sampling frequency
- name : string
- Name of the component, Standard visr.Component construction argument
- parent : visr.CompositeComponent
- Containing component if there is one, None if this is a top-level component of the signal flow.
- calibrationPort: int
- A UDP port number. Packets sent to this port trigger the calibration.
- razorArg: keyword list
- Set of parameters to the RazorAHRS. See this class for parameter documentation.