
Natural 3D Action Recognition
Simon Hadfield and Richard Bowden.Overview
Attempting to recognise human actions in video is a well established computer vision task, with applications to assisted living, surveillance and video indexing/retrieval. Performing action recognition in unconstrained situations ("in the wild") as opposed to in the lab, is very difficult. In general there is massive variations between examples of the same action (called intra-class variation). The task is made even more challenging when complicated actions in the real (3D) world, are viewed in a 2D image or video. A great deal of information is lost. The recent rise of 3D footage (including 3D TV channels, 3D home media and commercial depth sensors such as Kinect), provides an opportunity to overcome this.
How should we use 3D data?
This is an emerging field of research, and the best way to make use of this 3D visual data is currently unclear, especially outside lab conditions. Within the project, we explored a wide variety of techniques developed during the extensive prior research on action recognition with 2D data. We evaluate which of these techniques can be usefully adapted to the new data source. We also explored a number of novel techniques designed specifically for 3D data, including 3D motion field estimation.
To help this field of research develop, a new dataset was collected and made available to the research community. This dataset is called Hollywood3D as it follows a similar approach to the popular Hollywood and Hollywood-2 datasets. In addition, a broad baseline evaluation was undertaken on the dataset, including many extensions to existing techniques to account for the 3D data. The source code to reproduce all these evaluations was also made freely available.
Method
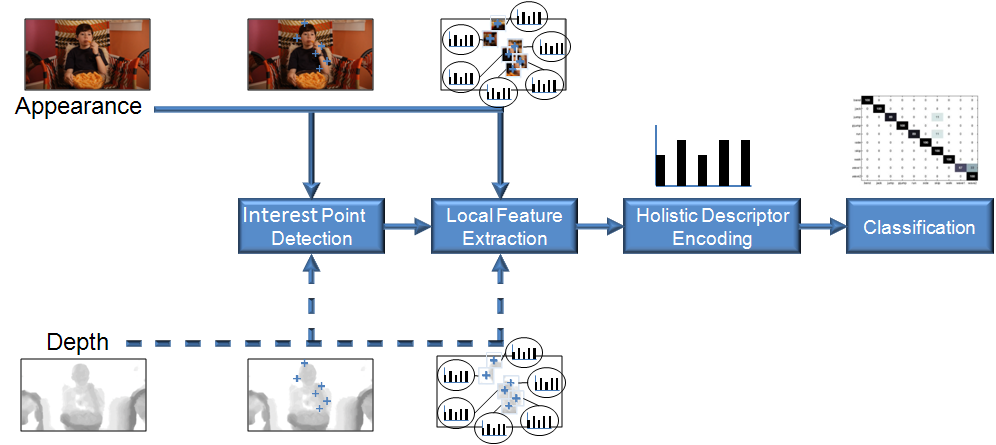
To explore the best ways to use 3D visual data in natural action recognition, the pipeline shown below was followed.
- First salient parts of the image are identified.
- Next, the information from a small region around these "interest points" is encoded into a feature representation.
- These local features are accumulated spatially and temporally across the video, providing invariance to actions occuring at different different space-time locations in the video.
- Finally, these holistic descriptors are fed into a machine learning system to recognise which type of action is occuring
When only appearance inputs are considered this is a standard pipeline for natural action recognition with 2D data. We explored various methods to exploit depth data at 2 places in the pipeline.
3.5D and 4D saliency measures
A number of standard definitions of image saliency were adapted to exploit depth data. These include:
- The Harris measure, designed to find corners in the image

- The Determinant of Hessian measure, designed to find blobs and
saddles

- The Separable Linear Filters approach, designed to be extremely
fast, and to find both corners and blobs
For action recognition, these techniques are traditionally 3D with 2 spatial dimensions in the image and one additional time dimension.

We explore 2 different approaches to incorporating depth into the formulation. First is what we term 4D interest points (3 spatial dimensions from the real world, + time). Here the equations for each saliency measure are modified to account for the change in dimensionality. Thus these measures identify specific patterns of colour gradient within a 4D volume.
We also propose 3.5D variants of these saliency measures. In this formulation appearance and depth are treated as 2 complimentary 3D (2 spatial and 1 temporal dimension) streams. Saliency is evaluated in both streams and aggregated. This approach allows us to use depth data to detect salient points on the boundary of textureless objects, and to use appearance to find salient points on objects with a smooth structure.
In addition to these salient point detection schemes, we also explored an alternative approach using densely sampled trajectories (see here).
Extensions of previous local features
At the local feature encoding stage, we explored extensions to 2 common techniques from the 2D action recognition literature. First, the Relative Motion Descriptor or RMD (see here) which describes a video sequence in terms of the distribution of saliency (using the various measures above). By accumulating the saliency within a 4D integral volume, we could describe patterns of saliency in 3D space and over time.
We also implemented the bag of visual words descriptor which has proved extremely successful in previous research. Originally this feature encoding was based on colour gradients and the 2D motion field. We integrated structural information in a similar manner
New local features using 3D motion fields
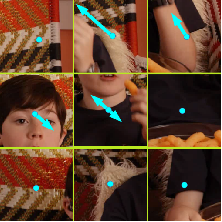
We also developed a new class of feature descriptors based on the estimated 3D motion field (more details on our research estimating these motion fields is available here). An example of an estimated 3D motion field, and a visualisation of the encoded features is shown below
In order to make optimal use of these motion features when recognising actions in the wild, we found it was necessary to incorporate additional invariances. Thus we developed a specialised pipeline for stereo sequence calibration (and made the resulting calibrations available here), and explored viewpoint invariant encoding schemes. The 3 different encoding schemes developed (Re-ordering, Bases from max flow, Bases via PCA) are illustrated below.


Results
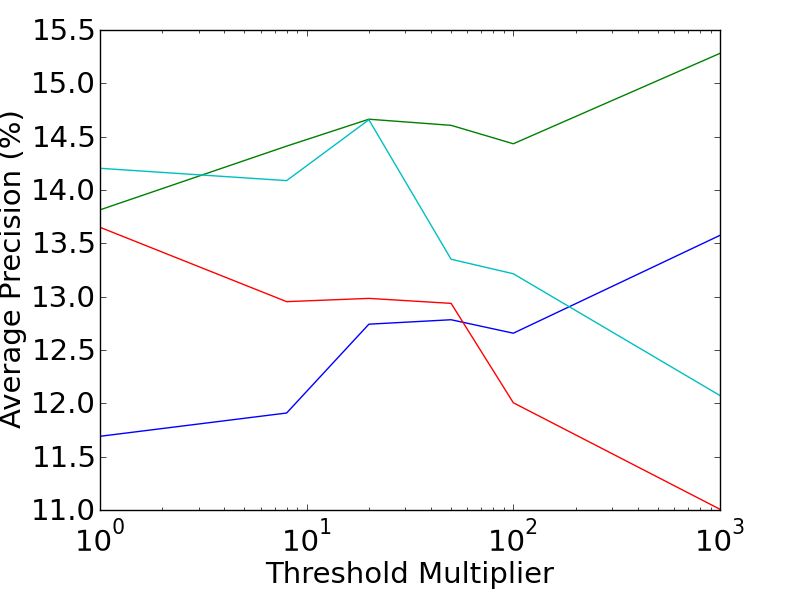
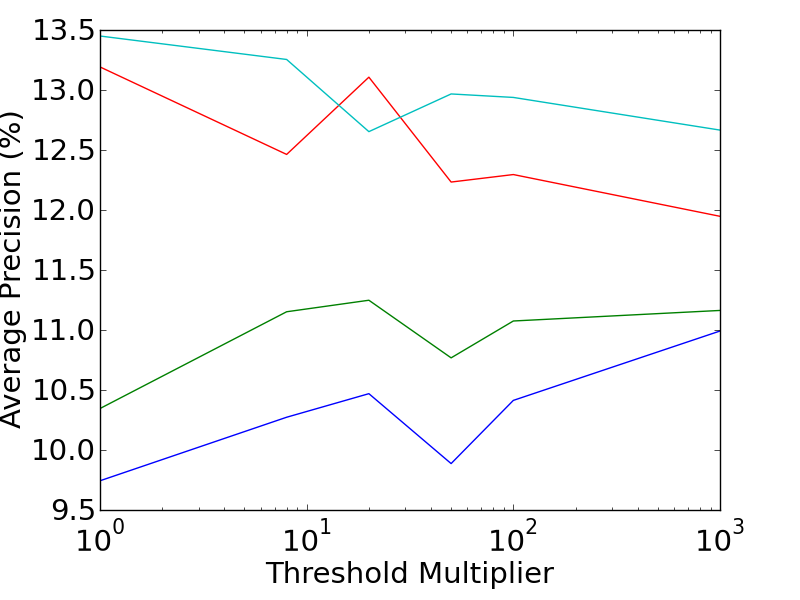
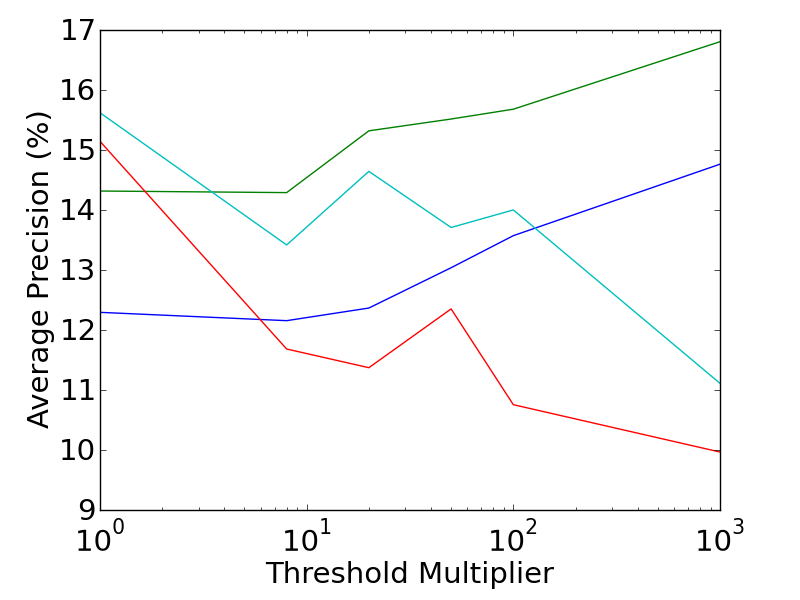
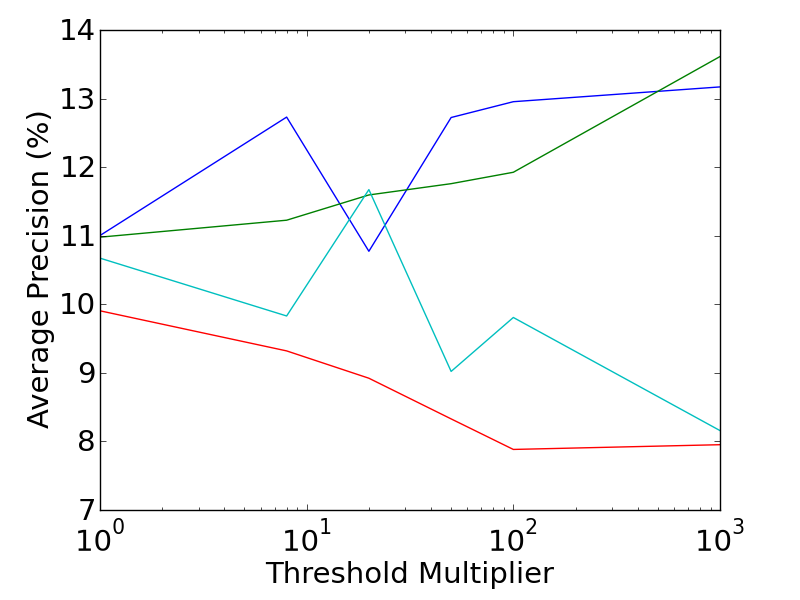
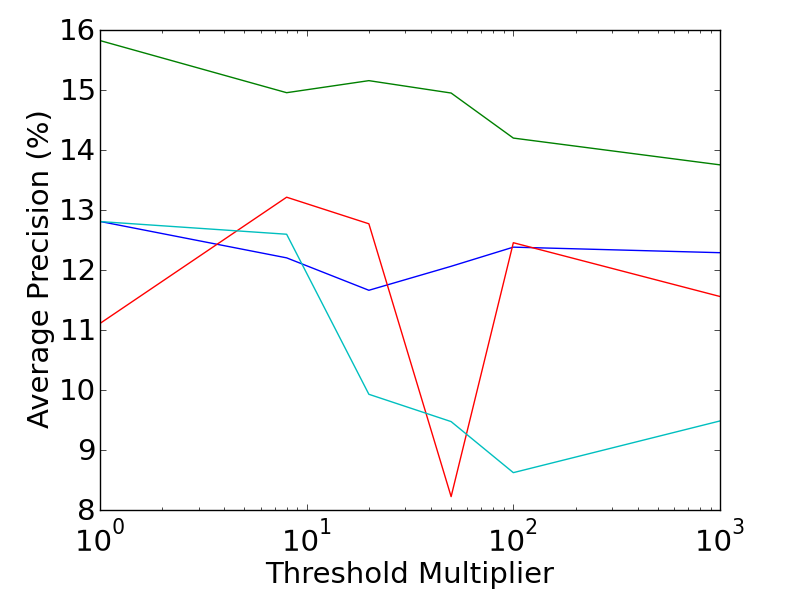
The performance of the various combinations of extended saliency measures and extended feature descriptors are shown in the graphs below. The Mean Average Precision is plotted against the saliency threshold (which controls the trade-off between dense features, and descriptive features). It is interesting to note the differing directions of the trends between the feature types. The performance of RMD features generally improves as features become sparser and more descriptive, while the Bag of Visual Words prefers more dense features.
More detailed results can be found in the related publications, including an analysis of the 3D motion features, which provide a 40% improvement in accuracy over the best alternative technique. In addition, a leaderboard which is kept up to date with the current state of the art performance, can be found here.
Publications
Hollywood 3D: Recognizing Actions in 3D Natural Scenes (Simon Hadfield, Richard Bowden), In Proceeedings, IEEE conference on Computer Vision and Pattern Recognition (CVPR), IEEE, 2013. [Poster], [Dataset and Code], [Citations]
Natural action recognition using invariant 3D motion encoding (Simon Hadfield, Karel Lebeda, Richard Bowden), In Proceedings of the European Conference on Computer Vision (ECCV), Springer, volume 8690, 2014. [Poster] [Citations]
Publications relating to 3D motion estimation
Scene Particles: Unregularized Particle Based Scene Flow Estimation (Simon Hadfield, Richard Bowden), In IEEE Trans. on Pattern Analysis and Machine Intelligence (PAMI), volume 36, 2014. [Citations]
Scene Flow Estimation using Intelligent Cost Functions (Simon Hadfield, Richard Bowden), In Proceedings of the British Conference on Machine Vision (BMVC), 2014. [Extended abstract], [Poster], [Supplementary results]
Acknowledgements
This work was part of the EPSRC project “Learning to Recognise Dynamic Visual Content from Broadcast Footage“ grant EP/I011811/1.