Rule Induction code
Rule induction in the context of automated sports video annotation.
- Release Notes
- Software Download (.zip)
Any questions/comments, please contact Dr. Aftab Khan or Dr. David Windridge.
ACASVA Actions Dataset
Nazli FarajiDavar and Teofilo deCampos
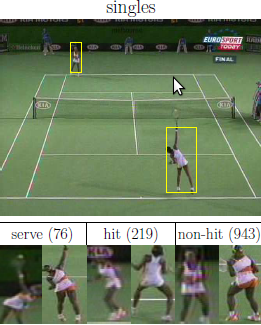

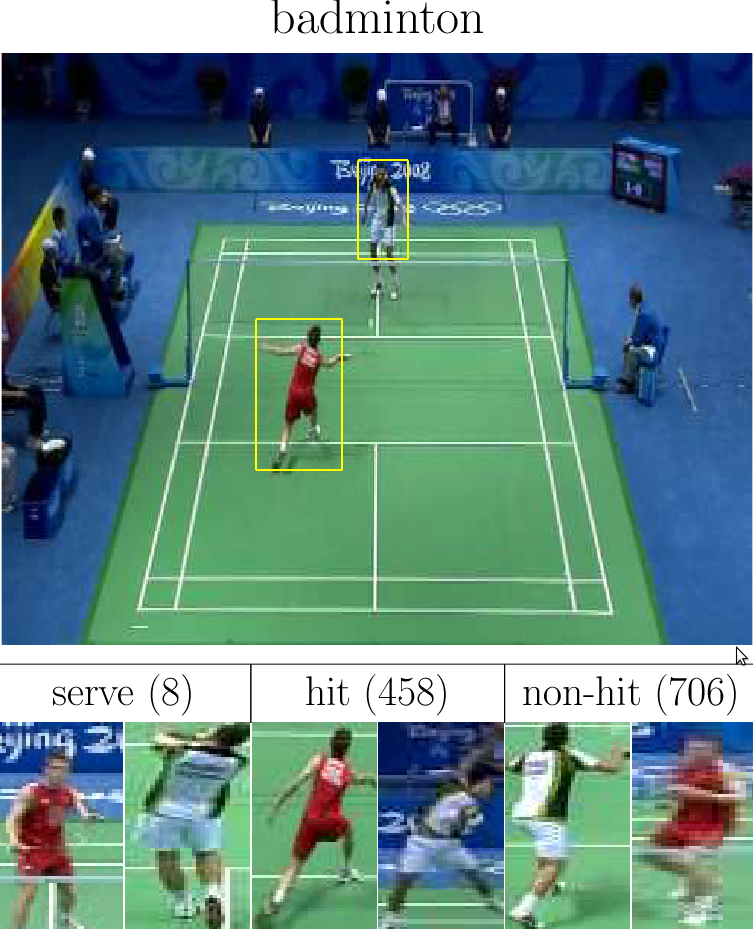
Player's action recognition is one of the challenges in the ACASVA project. The goal is to classify each action sample into three classes: Non-Hit, Hit and Serve. We have done simple classification experiments [3] and transductive transfer learning experiments [1][2]. The splits of data (for training, validation, testing) are done per game match, please see the references below for further detail.
Following deCampos et al [3], we used HOG3D descriptors extracted on player bounding boxes. Two different sets of feature extraction parameters were used: the 960D parameters (4x4x3x20) optimised for the KTH dataset and the 300D parameters (2x2x5x5x3) optimised for the Hollywood dataset (see Alexander Klaser's page for details). In our preliminary experiments, we found that the KTH parameters (960D) give better results for the tennis dataset.
The table below summarises the datasets. Each row refers to a video and a zip file was created for each type of HOG3D vector (dimensionality value). The size of each zip file is from 2 to 4MB.
| label | sport | gender | number | competition | year | Non-Hit | Hit | Serve | dimensionality |
| TWSA03 | Tennis | Women | Single | Australia | 2003 | 944 | 214 | 72 | 300 /960[1][3] |
| TMSA03 | Tennis | Men | Single | Australia | 2003 | 1881 | 469 | 123 | 300 /960 [2] |
| TWSJ09 | Tennis | Men | Single | Japan | 2009 | 859 | 224 | 59 | 300 /960 |
| TWDA09 | Tennis | Women | Double | Australia | 2009 | 1064 | 135 | 36 | 300 /960[1][3] |
| TWDU06 | Tennis | Women | Double | US | 2006 | 3269 | 405 | 77 | 300 /960 |
| BMSB08 | Badminton | Men | Single | Beijing | 2008 | 706 | 458 | 8 | 300 /960[2] |
This dataset was designed for the
Each file contains HOG3D data extracted from one match of tennis or
badminton. Because the conditions are different (illumination,
athletes, clothes, etc), this dataset poses an interesting application
scenario for transductive transfer learning methods. For example, a
game of badminton can be used for training, a first game of tennis can
be used for transfer (or domain adaptation) and a second game of
tennis can be used as the test set.
An alternative usage scenario is to evaluate methods that are able to
learn the structure of a temporal pattern. The table below shows a typical
sequence of actions in a tennis game. The following pattern becomes clear:
only one paper can hit the ball at a given instant, and hits are normally
followed by inactivity of both players, because when the tennis ball is bouncing on
the floor, none of the players are hitting it.
The following papers give further descriptions of this dataset and experiments: [1] N. FarajiDavar, T. deCampos, J. Kittler and F.Yan
[2] N. FarajiDavar, T. deCampos, D. Windridge, J. Kittler and W. Christmas
[3] T. deCampos, M. Barnard, K. Mikolajczyk, J. Kittler, F. Yan, W. Christmas and D. Windridge
Usage
transductive transfer learning experiments
published in the references below.
time stamp
action of far player
action of near player
479 Serve Non-Hit 503 Non-Hit Non-Hit 526 Non-Hit Hit 573 Non-Hit Non-Hit 592 Hit Non-Hit 636 Non-Hit Non-Hit 664 Non-Hit Hit
References
Transductive Transfer Learning for Action Recognition in Tennis Games
In 3rd International Workshop on Video Event Categorization, Tagging and Retrieval for Real-World Applications (VECTaR), in conjunction with 13th Internatinal Conference on Computer Vision, Barcelona, Spain 2011
Domain Adaptation in the Context of Sport Video Action Recognition
In Domain Adaptation Workshop, in conjunction with NIPS, Sierra Nevada, Spain 2011
An evaluation of bags-of-words and spatio-temporal shapes for action recognition
In IEEE Workshop on Applications of Computer Vision (WACV), 2011
A copy of this dataset is available at the mldata.org repository, doi:10.5881/ACASVA-ACTIONS-DATASET.